



2024년 6월 12일

An Image is Worth 32 Tokens for Reconstruction and Generation
(Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen)

Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
픽셀 패치 기반 VQ 대신 Semantic Latent 기반 토큰화로 필요 토큰 수를 줄일 수 있다는 아이디어. ViT에 레지스터 토큰을 입력한 다음 이 레지스터 토큰을 Latent로 사용하는 방법입니다. 재미있네요.
다만 Latent 토큰들 사이에 순서가 있지는 않을 것이라 Autoregressive 세팅과는 불일치가 있을 듯 합니다. (물론 Raster Order가 딱히 훨씬 더 나은 것은 아니겠지만요.) 그리고 이런 토큰화 방법들에 대해서는 OCR과 텍스트 생성이 잘 되는가라는 질문을 하게 되죠.
#image-generation #vq
Simple and Effective Masked Diffusion Language Models
(Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, Volodymyr Kuleshov)

While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
Masked Diffusion을 사용한 텍스트 생성. 기존의 Masked Diffusion보다 더 심플하고 분산이 작은 Objective를 사용했다는 것이 핵심 같네요.
Diffusion을 사용한 텍스트 생성이 토큰의 생성 순서 문제를 잡을 수 있지 않을까 하는 생각을 합니다. 다만 요즘 스트리밍 생성에 관심이 집중되고 있는 터라 예전보단 약간 우려가 되긴 하네요.
#diffusion
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
(Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi)

Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named \textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4% success rate on the MATH benchmark, a 36% relative improvement from the 51% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
MCTS가 또 나왔네요. Math-Shepherd (https://arxiv.org/abs/2312.08935) 와 같이 정답을 사용해 Process Supervision을 생성하는 것이 목적인데 샘플의 생성 효율성을 MCTS를 사용해 높이겠다는 것이 목표입니다.
이쪽 연구들이 많이 나오고 있는 터라 이전에도 썼던 것처럼 집중적으로 대규모 실험을 하면 지금 시점에서도 뭔가 되는 것이 아닐까 하는 생각이 드네요.
#reward-model #search
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
(Di Zhang, Jiatong Li, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, Wanli Ouyang)

This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
이쪽도 MCTS 결합이군요. 여기서는 Self Refine (https://arxiv.org/abs/2303.17651) 과 Self Evaluation을 트리 탐색 과정에 결합했다는 것이 요점입니다.
#search
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
(Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, Weizhu Chen)
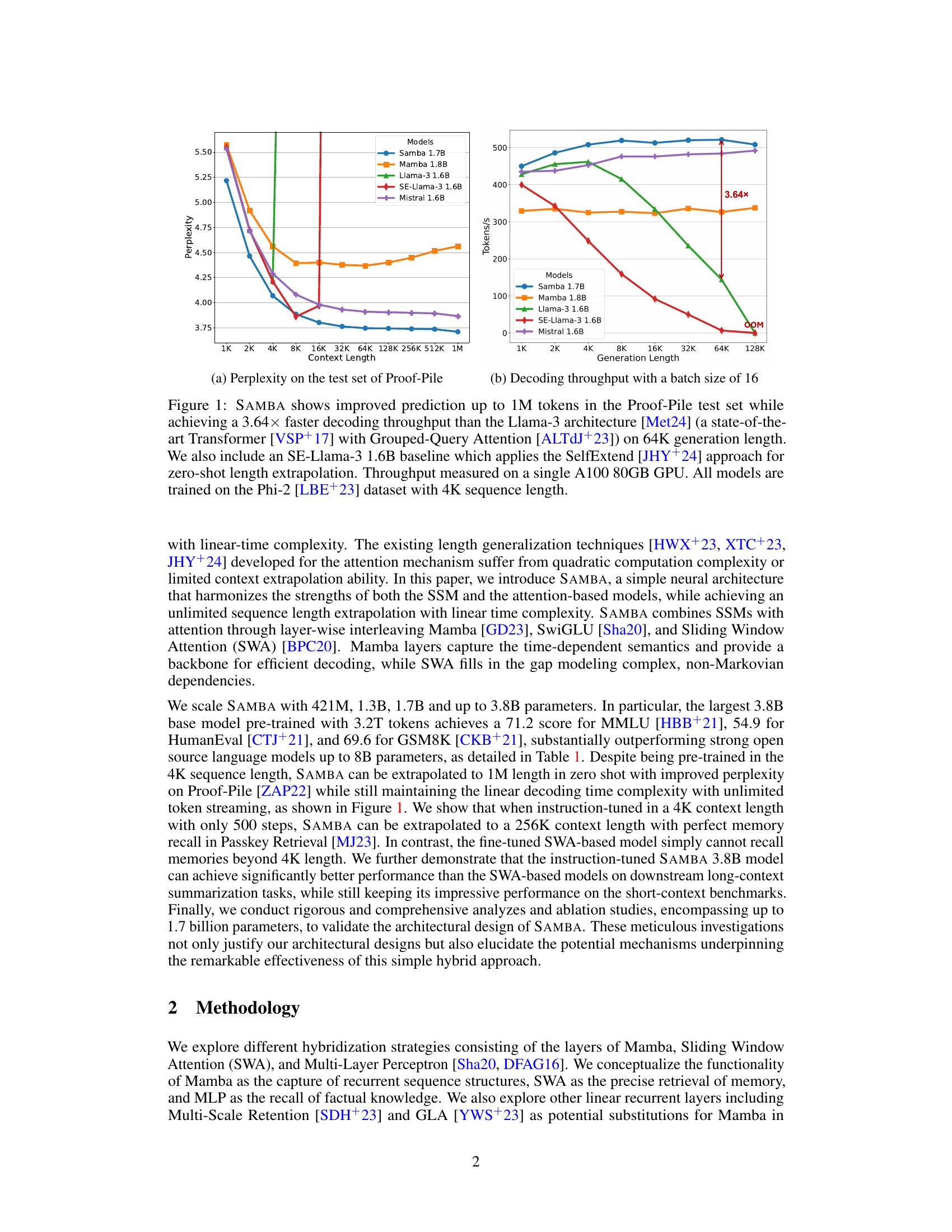
Efficiently modeling sequences with infinite context length has been a long-standing problem. Past works suffer from either the quadratic computation complexity or the limited extrapolation ability on length generalization. In this work, we present Samba, a simple hybrid architecture that layer-wise combines Mamba, a selective State Space Model (SSM), with Sliding Window Attention (SWA). Samba selectively compresses a given sequence into recurrent hidden states while still maintaining the ability to precisely recall memories with the attention mechanism. We scale Samba up to 3.8B parameters with 3.2T training tokens and show that Samba substantially outperforms the state-of-the-art models based on pure attention or SSMs on a wide range of benchmarks. When trained on 4K length sequences, Samba can be efficiently extrapolated to 256K context length with perfect memory recall and show improved token predictions up to 1M context length. As a linear-time sequence model, Samba enjoys a 3.73x higher throughput compared to Transformers with grouped-query attention when processing user prompts of 128K length, and 3.64x speedup when generating 64K tokens with unlimited streaming. A sample implementation of Samba is publicly available in https://github.com/microsoft/Samba.
Mamba + Sliding Window Attention. Griffin (https://arxiv.org/abs/2402.19427) 과 비슷한 세팅인데 Attention이 1:1로 들어가는군요. 은근슬쩍 Phi3의 3.2T 토큰으로 학습시킨 결과를 가져왔군요.
Griffin에서도 나타났지만 Sliding Window Attention과의 조합이 Associative Recall 과제에서 문제가 생기는 듯 한데 그 부분에 대한 실험이 없다는 것은 조금 아쉽네요.
#state-space-model
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
(Yunzhen Feng, Elvis Dohmatob, Pu Yang, Francois Charton, Julia Kempe)

Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes. We illustrate our theoretical predictions on two practical problems: computing matrix eigenvalues with transformers and news summarization with large language models, which both undergo model collapse when trained on model-generated data. We show that training from feedback-augmented synthesized data, either by pruning incorrect predictions or by selecting the best of several guesses, can prevent model collapse, validating popular approaches like RLHF.
합성 데이터로 모델을 학습시키면 모델이 Collapse 하는데, 피드백 (샘플 선택) 메커니즘이 들어가면 성능 개선이 가능한가? 에 대한 연구. 가능하다고 합니다.
합성 데이터는 크게 두 가지 방향을 생각해볼 수 있겠죠.
기존 데이터에서 더 많은 정보를 끌어내는 방법으로서의 합성 데이터.
합성 데이터에 피드백 등으로 추가적인 정보를 주입하는 방법.
둘 모두 유망한 방법 듯 하고 두 영역 모두에서 중요한 진전들이 나오지 않을까 싶네요.
#synthetic-data