



2024년 5월 20일

Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(Gemini Team)
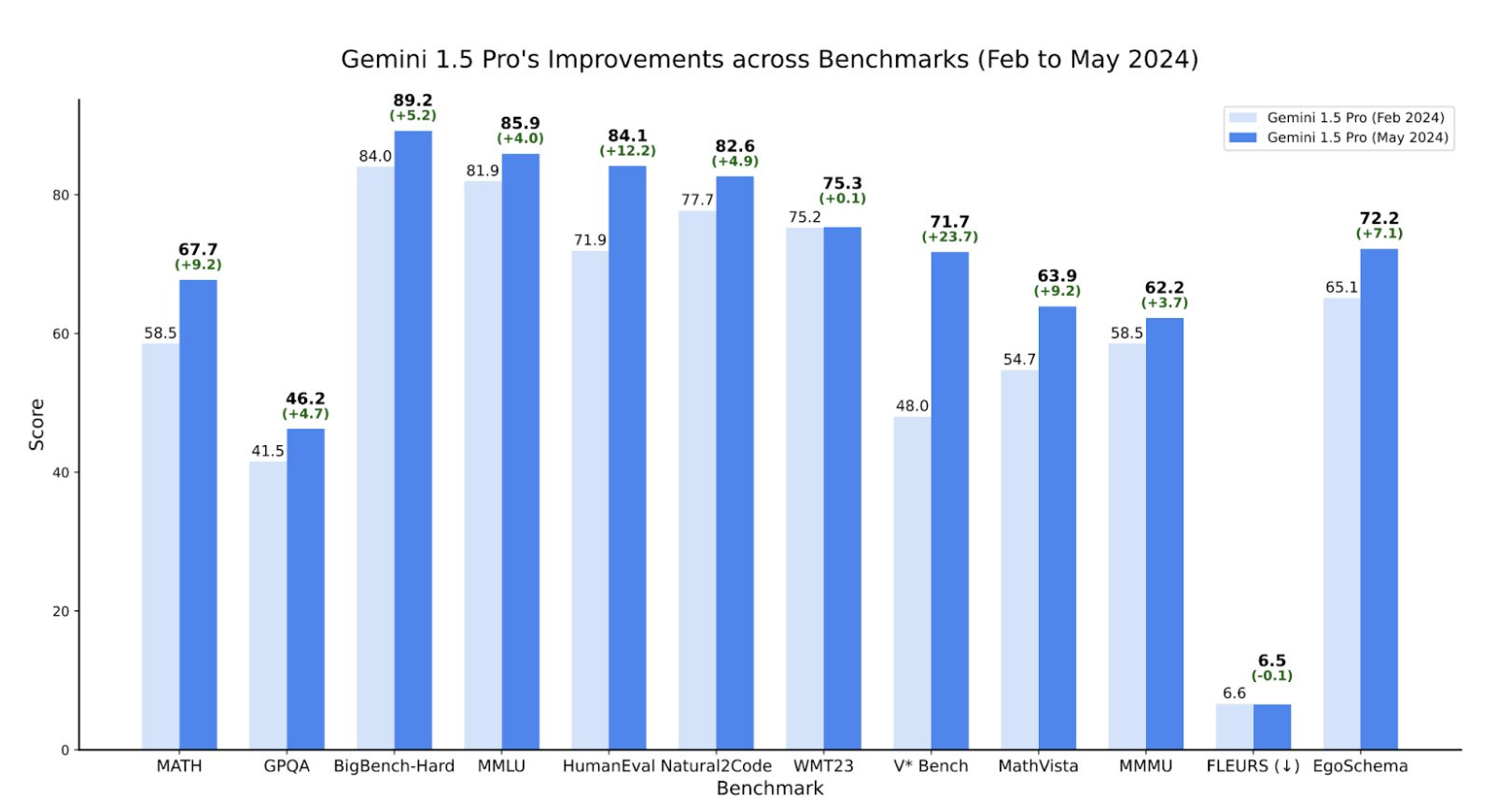
In this report, we introduce the Gemini 1.5 family of models, representing the next generation of highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. The family includes two new models: (1) an updated Gemini 1.5 Pro, which exceeds the February version on the great majority of capabilities and benchmarks; (2) Gemini 1.5 Flash, a more lightweight variant designed for efficiency with minimal regression in quality. Gemini 1.5 models achieve near-perfect recall on long-context retrieval tasks across modalities, improve the state-of-the-art in long-document QA, long-video QA and long-context ASR, and match or surpass Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5’s long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 3.0 (200k) and GPT-4 Turbo (128k). Finally, we highlight real-world use cases, such as Gemini 1.5 collaborating with professions on their completing their tasks achieving 26 to 75% time savings across 10 different job categories, as well as surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini 1.5 Pro 테크니컬 리포트가 업데이트됐습니다. Gemini 1.5 Pro가 그동안 여러 프리트레이닝과 포스트 트레이닝 이터레이션을 거치며 Gemini 1.0 Ultra를 상회하는 성능에 도달했다는 것이 나와 있네요.
Gemini 1.5 Pro의 경우엔 수학 특화 모델도 만들었고 이 모델은 MATH에서 80-90% (!) 스코어를 달성했습니다.
Gemini 1.5 Flash에 대한 정보도 나와있는데 꽤 흥미로운 점이 많네요. Parallel Layer를 사용했고 Gemini 1.5 Pro를 사용한 Knowledge Distillation이 들어갔습니다. 거기에 Second-order Optimizer를 사용했군요. Second-order Optimizer를 실용적인 LLM 학습에 사용한 것은 최초가 아닌가 싶네요. (LLM 외에도 사례는 별로 없지만요.) 어떤 방법을 썼는지 알아내는 것도 재미있겠네요. (Shampoo? Sophia? 혹은 그 외?) 공개된 방법이라면 Rohan Anil의 논문 중에 있지 않을까 싶습니다.
추가로 Flash-8B라는 더 작은 모델도 만들었는데 그렇다는 것은 1.5 Flash는 8B보다는 유의미하게 크다는 의미겠죠. 20B 근방이 아닐까 생각해봅니다.
구글의 프리트레이닝 역량은 레포트에서도 잘 드러나 있는 듯 하고 문제는 포스트트레이닝이겠죠. 1.5 Pro/Flash 모두 API가 공개되었으니 한 번 테스트해보는 것도 의미가 있을 듯 싶습니다. 정렬 스타일이 달라졌다는 것 자체는 체감할 수 있네요.
Observational Scaling Laws and the Predictability of Language Model Performance
(Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto)

Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
벤치마크에 대한 Scaling Law도 많이 발전하고 있네요. 여기서는 벤치마크의 스코어들을 차원 축소한 다음 모델 클래스 (Llama 등) 내에서의 연산량의 증가와 차원 축소해서 추출한 요인 사이의 관계를 사용해서 벤치마크 스코어에 대한 Scaling Law를 만들었네요.
복잡하게 쓰긴 했는데 결국 다층 모형입니다.
가장 흥미로운 것은 각 모델 클래스 내에서 연산량과 요인에 대해 선형적인 관계가 있고 이 직선의 기울기가 연산 효율성을 의미한다는 것입니다. 이 기울기가 낮다면 뭔가 잘못 하고 있다는 의미라는 것이겠죠.
여담이지만 주요 요인은 일반 능력, 추론 능력, 프로그래밍 능력 세 가지로 레이블링을 했는데 이 요인들의 가중치를 보면 가장 중요한 3대 벤치마크는 MMLU, GSM8K, HumanEval이라고 할 수 있을 것 같네요.
#scaling-law
DINO as a von Mises-Fisher mixture model
(Hariprasath Govindarajan, Per Sidén, Jacob Roll, Fredrik Lindsten)

Self-distillation methods using Siamese networks are popular for self-supervised pre-training. DINO is one such method based on a cross-entropy loss between K-dimensional probability vectors, obtained by applying a softmax function to the dot product between representations and learnt prototypes. Given the fact that the learned representations are L^2-normalized, we show that DINO and its derivatives, such as iBOT, can be interpreted as a mixture model of von Mises-Fisher components. With this interpretation, DINO assumes equal precision for all components when the prototypes are also L^2-normalized. Using this insight we propose DINO-vMF, that adds appropriate normalization constants when computing the cluster assignment probabilities. Unlike DINO, DINO-vMF is stable also for the larger ViT-Base model with unnormalized prototypes. We show that the added flexibility of the mixture model is beneficial in terms of better image representations. The DINO-vMF pre-trained model consistently performs better than DINO on a range of downstream tasks. We obtain similar improvements for iBOT-vMF vs iBOT and thereby show the relevance of our proposed modification also for other methods derived from DINO.
DINO의 학습 Objective를 vMF 분포 Mixture 모델로 연결해봤을 때 vMF Mixture에 있어야 할 Normalization constant가 빠져 있는데 이 상수의 부재가 학습 불안정성을 유발한다는 아이디어. 재미있네요.
#contrastive-learning