



2024년 5월 1일

Better & Faster Large Language Models via Multi-token Prediction
(Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve)
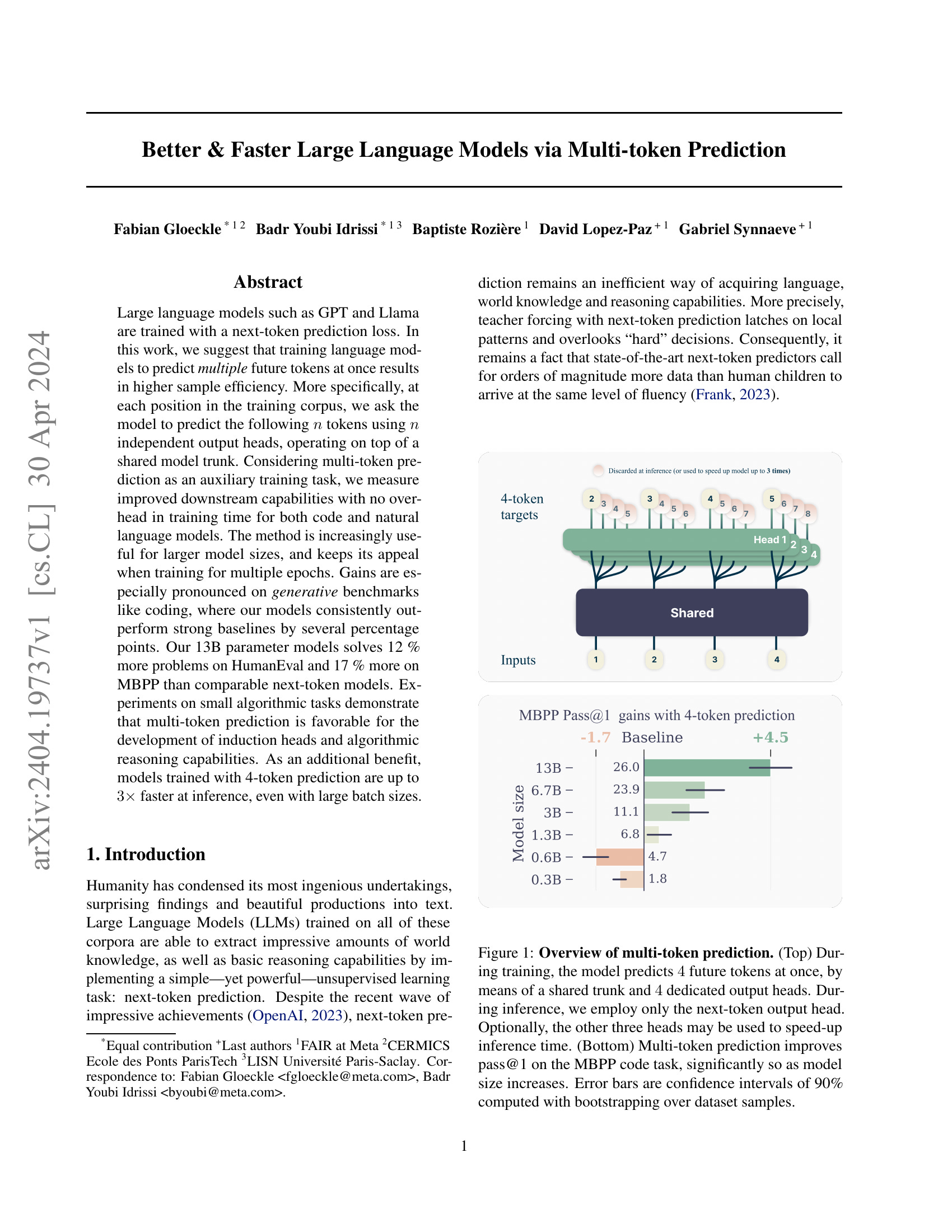
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
바로 다음 토큰 뿐만 아니라 추가로 여러 토큰을 더 예측하도록 학습하는 방법. 사실 이렇게 여러 토큰을 예측하는 방법은 샘플링 속도 가속 측면에서 지속적으로 나오고 있죠. (https://arxiv.org/abs/1811.03115, https://arxiv.org/abs/2401.10774)
이 논문은 여러 토큰을 예측하는 것이 샘플링 가속 뿐만 아니라 성능 자체에도 도움이 될 수 있다는 이야기를 합니다. 작은 모델에서는 손해가 나타나지만 모델이 커지면 오히려 성능이 향상된다는 것이죠. 학습 토큰이 증가하면 향상폭이 감소하는 것 같기도 합니다만 여하간 향상이 나타나는 경우가 있다는 것이 흥미롭네요.
논문에서도 인용하고 있지만 (https://arxiv.org/abs/2403.06963) 다음 토큰만 예측하도록 하는 것이 학습 시그널을 약화시키는 영향이 있을 수 있습니다. 그런 의미에서 마스킹 같은 방법들과 같이 생각해보면 재미있을 듯 하네요.
새로운 학습 Objective는 탐구할 가치가 있는 주제일 듯 합니다. 또한 작은 규모에서는 효과가 있었지만 큰 규모에서 효과가 사라지는 사례들과 반대로 작은 규모에서는 손해였다가 큰 규모에서는 도움이 되는 사례들도 있을 수 있다는 증거가 될 수 있을 듯 하네요.
#pretraining #autoregressive-model
KAN: Kolmogorov-Arnold Networks
(Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, Max Tegmark)

Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Kolmogorov-Arnold representation theorem (https://en.wikipedia.org/wiki/Kolmogorov–Arnold_representation_theorem), 즉 임의의 다변수 연속함수를 Univariate 연속함수의 유한합으로 표현할 수 있다는 정리에 근거해 모델을 구성했습니다.
Kolmogorov Arnold 정리의 문제는 이 임의의 함수에 대해 Univariate 함수가 Smooth하다고 보장할 수 없다는 것이었습니다. 그런데 그에 대해 Smooth한 함수로 할 수 있는 만큼 하면 안 될까? 하는 아이디어네요.
여기서는 함수로 B-Spline을 사용했습니다. 결과적으로는 각 Weight마다 B-Spline 계수가 들어가는 형태라 대규모에서 실용적이기는 어려울 듯 합니다만 Scaling 등의 측면에서 흥미로운 결과가 나왔네요. 또한 이 Spline을 사용해 일종의 Symbolic Regression 문제에 접근하기도 했습니다.
이런 연구는 오랜만이라 재미있네요.
#mlp
Iterative Reasoning Preference Optimization
(Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, Jason Weston)

Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks (Yuan et al., 2024, Chen et al., 2024). In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer. We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy for Llama-2-70B-Chat from 55.6% to 81.6% on GSM8K (and 88.7% with majority voting out of 32 samples), from 12.5% to 20.8% on MATH, and from 77.8% to 86.7% on ARC-Challenge, which outperforms other Llama-2-based models not relying on additionally sourced datasets.
문제에 대해 Chain of Thought Rationale을 생성하고 정답이 맞은 경우를 Positive, 맞지 않은 경우를 Negative로 해서 DPO Loss와 Positive에 대한 NLL Loss로 학습시킵니다. 그리고 이렇게 학습한 모델로 Chain of Thought 생성부터 다시 반복하네요.
답이 주어진다면 많은 것을 할 수 있다는 사례가 하나 더 추가됐네요. 이제 답을 어떻게 찾아낼 것인가가 점점 더 문제가 될 듯 합니다.
#self-improvement