



2024년 4월 17일

Reka Core
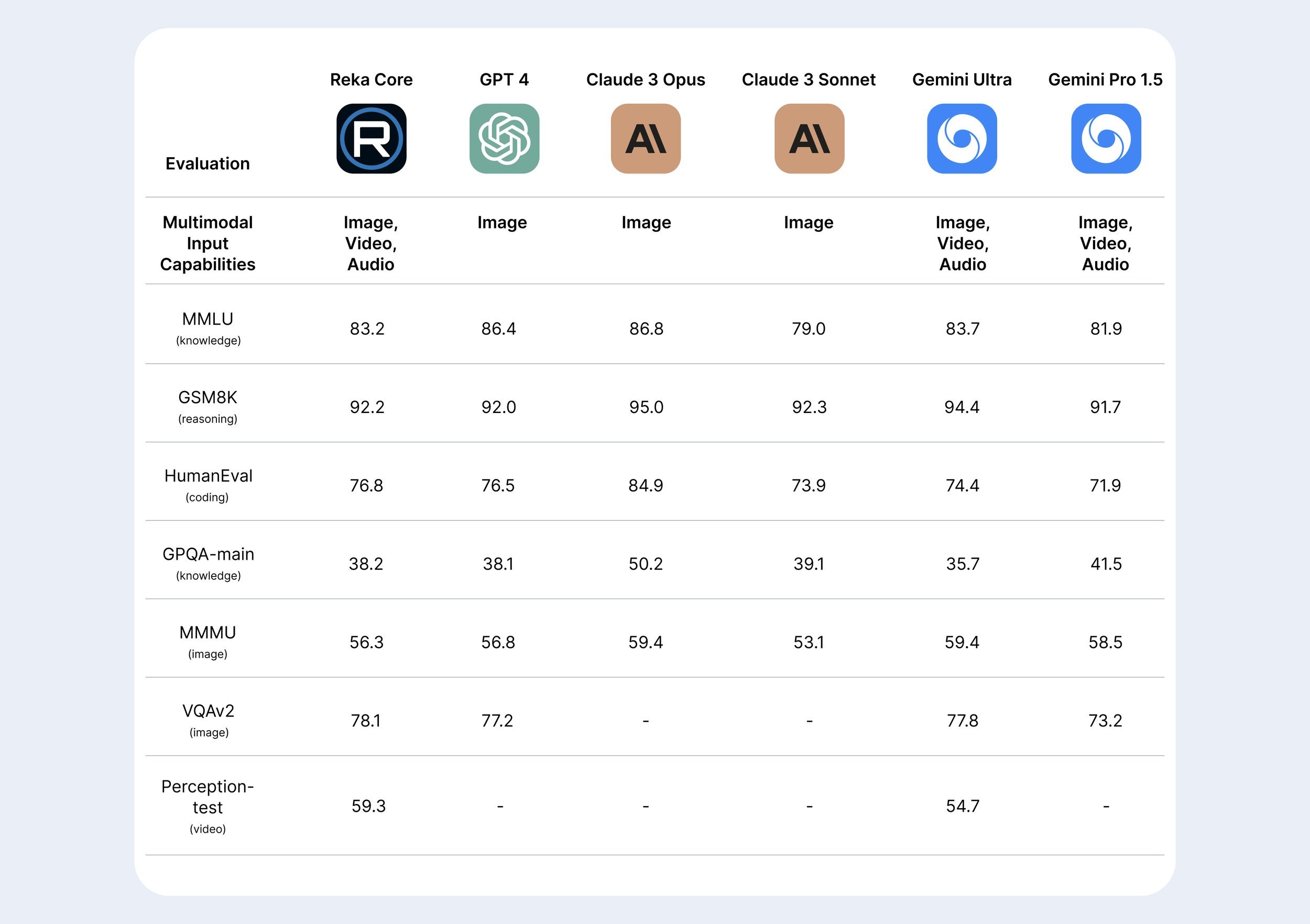
Reka에서 Reka Core를 공개하면서 Reka Flash와 Edge에 대한 정보도 공개했습니다. 일단 최고 성능 모델인 Reka Core는 Claude 3 Opus와 Sonnet 중간 정도에 있는 성능입니다. ELO도 대략 그 사이에 있습니다. Mistral Large 보다 좀 더 고성능이라고 할 수 있겠네요. 그러나 이쪽은 이미지/비디오/오디오에 대한 Multimodal 모델입니다.
학습 데이터의 카테고리를 보면 다음과 같습니다. 배타적인 분류가 아니기에 중복이 있을 수 있습니다. 5T 토큰을 기준으로 보면,
25% 코드 = 1.25T 30% STEM = 1.5T 25% 웹 크롤 = 1.25T 10% 수학 = 0.5T 15% Multilingual = 0.75T
Multi Epoch은 아니라고 합니다. (https://x.com/YiTayML/status/1779903430053761444) 웹 크롤의 비중이 상당히 작다는 것이 특징적입니다. 물론 1.25T도 총량으로는 적지는 않습니다. 다만 그 이상의 STEM, 수학 데이터를 어떻게 확보했는지는 의문이 있네요. DeepSeek Math에서 Common Crawl의 수학 관련 데이터를 탈탈 털어서 확보한 데이터의 규모가 120B 수준이습니다. (https://arxiv.org/abs/2402.03300) 아마도 책이나 논문 데이터를 굉장히 많이 확보한 것이 아닐까 싶습니다.
Gemma 7B가 6T, Mistral 7B도 6T 정도라고 하는데 Reka Edge 7B가 4.5T 정도로 이 두 모델을 상회하는 스코어를 달성했다는 것은 데이터 측면의 강점을 다시 보여주는 것이 아닐까 합니다.
모델 구조는 PaLM과 유사한데 인코더-디코더입니다. MoE는 아닙니다. 텍스트에는 인코더를 사용하지 않았다 같은 세팅은 아닐 듯 하고 센티널 토큰이 들어가 있다는 것을 보면 T5, UL2 계통의 모델일 가능성이 높습니다.
확보한 GPU는 H100 2.5K A100 2.5K 정도라고 합니다. 주로 H100으로 학습시켰다고 하고 추측컨데 3개월 정도 학습했다고 하면 70B 규모의 모델을 12T 정도 학습시킬 수 있지 않을까 싶네요. 물론 인코더-디코더이므로 성능 패턴이 많이 다르긴 하겠죠.
비교적 높은 Learning Rate를 사용했다고 합니다. 학습이 가능한 한 가장 높은 Learning Rate를 사용하는 것이 좋다는 직관은 여전히 통하는 규칙인 듯 하네요.
#llm
Idefics2

HuggingFace에서 Idefics2와 SFT에 사용한 Instruction 데이터셋 컬렉션인 The Cauldron (https://huggingface.co/datasets/HuggingFaceM4/the_cauldron) 을 공개했네요. OCR에 대한 강조가 많이 있네요. Vision Language로 할 수 있는 가장 가치 있는 일 중 하나가 OCR이긴 하죠.
#vision-language
Probing the 3D Awareness of Visual Foundation Models
(Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, Varun Jampani)

Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
Depth/Surface Normal/Correspondence Estimation으로 CLIP, DINO, StableDiffusion 같은 Vision 인코더 모델들의 3d Awareness를 측정했군요.
DINO와 Stable Diffusion이 꽤 좋은 성능을 보여줍니다. 다만 Correspondence에서 모델들이 모두 약한 모습을 보여주네요. 3D Consistency에 대해 문제가 있다는 의미가 됩니다.
비디오나 3D 데이터에 대해 Contrastive 혹은 Generative Objective로 학습된 인코더가 가장 우수한 특성을 보여줄 것 같다는 느낌이 드네요.
#vision
The Illusion of State in State-Space Models
(William Merrill, Jackson Petty, Ashish Sabharwal)

State-space models (SSMs) have emerged as a potential alternative architecture for building large language models (LLMs) compared to the previously ubiquitous transformer architecture. One theoretical weakness of transformers is that they cannot express certain kinds of sequential computation and state tracking (Merrill and Sabharwal, 2023), which SSMs are explicitly designed to address via their close architectural similarity to recurrent neural networks (RNNs). But do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no. Our analysis reveals that the expressive power of SSMs is limited very similarly to transformers: SSMs cannot express computation outside the complexity class ��0TC0. In particular, this means they cannot solve simple state-tracking problems like permutation composition. It follows that SSMs are provably unable to accurately track chess moves with certain notation, evaluate code, or track entities in a long narrative. To supplement our formal analysis, we report experiments showing that Mamba-style SSMs indeed struggle with state tracking. Thus, despite its recurrent formulation, the "state" in an SSM is an illusion: SSMs have similar expressiveness limitations to non-recurrent models like transformers, which may fundamentally limit their ability to solve real-world state-tracking problems.
체스 기보를 입력으로 받아 체스판의 최종 상태를 예측하는 것과 같은 상태 추적 과제에 대해서 State Space Model이 Transformer와 비슷하다는 분석. 가장 큰 문제는 Hidden State에 대한 Projection이 고정된 행렬이거나 게이트를 사용하는 경우에는 대각 행렬이라는 것이 문제입니다. 이런 제약을 걸면 표현력에 한계가 생긴다는 것이죠.
이에 대응하려면 다음 Hidden State를 계산하는 과정에 Nonlinearity를 주거나 게이트 행렬이 대각 행렬이라는 제약을 풀어야 합니다. 과거의 RNN과 비슷해지면서 병렬화와 계산 효율성에서 문제가 크죠.
병렬화나 계산 효율성과 표현력에는 어쩔 수 없는 트레이드오프가 있는 것이 아닌가 하는 생각도 듭니다.
#state-space-model
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
(Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou)

The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2-7B (1.75) and 13B (1.67). Code: https://github.com/XuezheMax/megalodon
이전에 나왔던 Mega (https://arxiv.org/abs/2209.10655) 모델의 개선이군요. EMA 기반 모델인데 기본적으로 State Space Model과 비슷합니다. Chunkwise Attention이 들어간다는 점에서는 이미 하이브리드 모델이라고 할 수도 있겠군요.
Mega에 복소수 기반 EMA, Causal Group Norm, FFN에 레이어를 건너뛴 Skip Connection을 연결하는 등의 트릭을 사용했군요. 7B/2T 레벨의 학습을 진행했습니다. 사실 Chunkwise Attention이 그렇게 미덥지(?) 않긴 합니다만.
#state-space-model
Compression Represents Intelligence Linearly
(Yuzhen Huang, Jinghan Zhang, Zifei Shan, Junxian He)

There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of "intelligence", we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 30 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
Bits Per Character와 벤치마크 성능에 대한 관계 추정. Common Crawl, GitHub, arXiv 코퍼스에서 BPC를 측정했습니다. 상관계수가 0.9 수준으로 잘 나옵니다.
코퍼스와 벤치마크를 다르게 한 경우나 코퍼스를 믹스한 경우에 대한 결과도 재미있네요. 서적 코퍼스에 대해 MMLU와의 상관계수가 더 높게 나왔다는 것도 흥미로운 결과입니다.
이 결과를 사용해 데이터셋을 구성하는 지침으로 사용할 수 있지 않을까 하는 생각도 드네요. 벤치마크와의 상관계수를 높이는 형태로 데이터셋을 전처리하거나 믹스할 수 있지 않을까 싶습니다.
#llm #dataset
Self-playing Adversarial Language Game Enhances LLM Reasoning
(Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, Nan Du)

We explore the self-play training procedure of large language models (LLMs) in a two-player adversarial language game called Adversarial Taboo. In this game, an attacker and a defender communicate with respect to a target word only visible to the attacker. The attacker aims to induce the defender to utter the target word unconsciously, while the defender tries to infer the target word from the attacker's utterances. To win the game, both players should have sufficient knowledge about the target word and high-level reasoning ability to infer and express in this information-reserved conversation. Hence, we are curious about whether LLMs' reasoning ability can be further enhanced by Self-Play in this Adversarial language Game (SPAG). With this goal, we let LLMs act as the attacker and play with a copy of itself as the defender on an extensive range of target words. Through reinforcement learning on the game outcomes, we observe that the LLMs' performance uniformly improves on a broad range of reasoning benchmarks. Furthermore, iteratively adopting this self-play process can continuously promote LLM's reasoning ability. The code is at https://github.com/Linear95/SPAG.
단어 하나를 주고 공격자는 그 단어를 말하지 않으면서 방어자가 자기도 모르게 말하게 하도록 하고 방어자는 그 단어를 맞히는 게임 (https://arxiv.org/abs/1911.01622) 을 사용해 RL을 하는 것으로 추론 능력을 향상시킬 수 있다는 결과.
이런 게임에서 습득한 능력이 다른 과제로 일반화 될 수 있다는 것이 흥미롭네요. RL을 위한 Reward를 설정하는 것이 문제였는데 다소간 인위적인 과제라도 그것이 다른 과제에 대한 향상으로 이어질 수 있다면 그것도 한 가지 방향이 되겠죠.
#rl #llm