



2024년 4월 11일

Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
(Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, J. Zico Kolter)
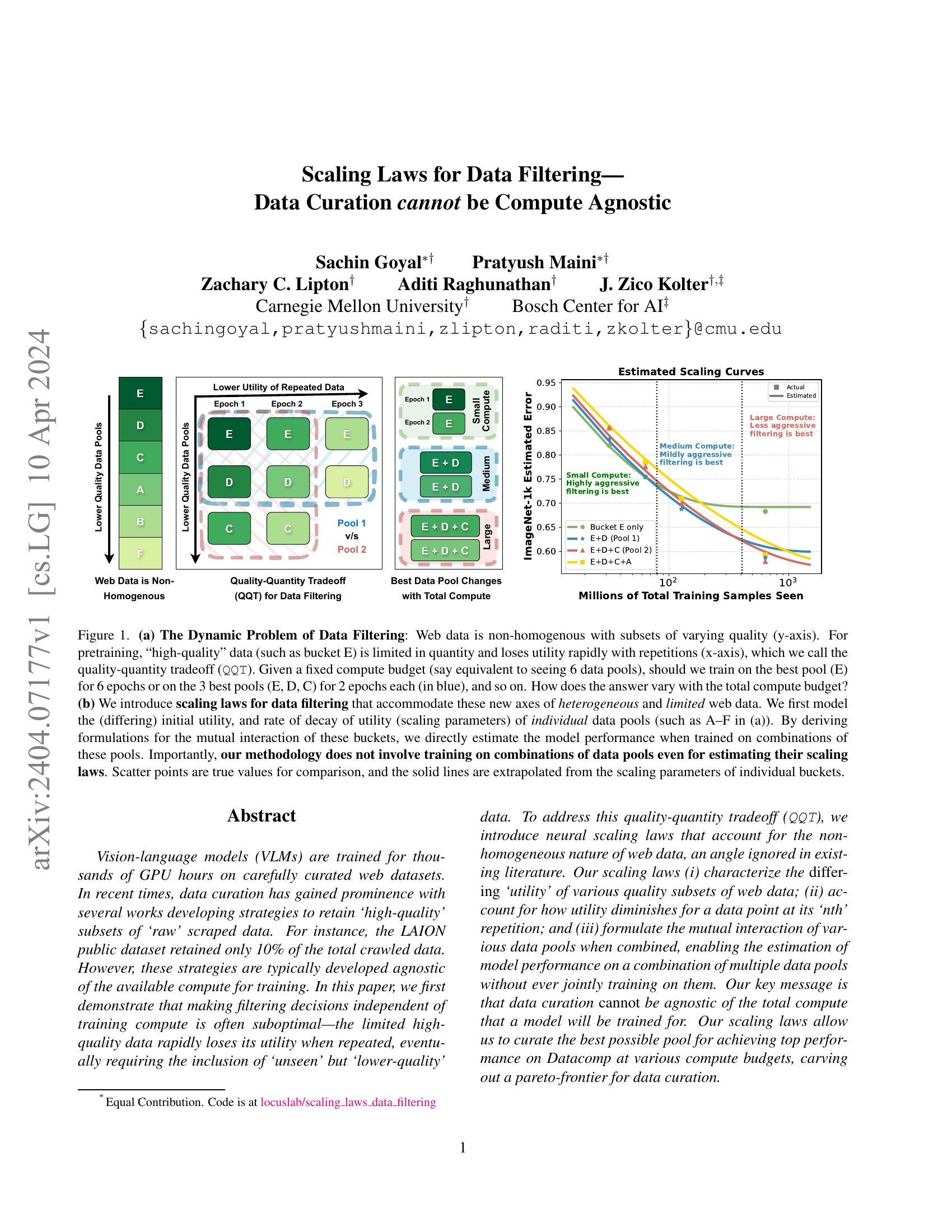
Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff (QQTQQT), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the differingdiffering 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them. Our key message is that data curation cannotcannot be agnostic of the total compute that a model will be trained for. Our scaling laws allow us to curate the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation. Code is available at https://github.com/locuslab/scaling_laws_data_filtering.
고퀄리티 데이터를 Multi Epoch 학습시키기 vs 낮은 퀄리티 데이터도 포함해서 1 Epoch 학습시키기라는 중요한 문제에 대한 탐색이네요. 총 학습량이 작을 때는 높은 퀄리티의 데이터만 쓰는 쪽이 낫고 학습량이 늘어날수록 낮은 퀄리티 데이터도 포함하는 쪽이 낫습니다. DeepSeek LLM (https://arxiv.org/abs/2401.02954) 에서 데이터의 퀄리티가 높아짐에 따라 모델 크기에 대한 Exponent가 증가했던 결과와 연결되는 결과인 것 같습니다.
아주 쓸모 없는 데이터가 아니라면 데이터를 필터링하는 것보다는 샘플의 퀄리티를 개선하기 위한 작업을 하는 쪽이 나을 수 있겠다는 생각이 드네요. 물론 주어진 연산량에서 최적 지점을 찾기 위한 Scaling Law 탐색을 먼저 해야겠지만요.
#scaling-law
RULER: What's the Real Context Size of Your Long-Context Language Models?
(Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Boris Ginsburg)

The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate ten long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only four models (GPT-4, Command-R, Yi-34B, and Mixtral) can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
Needle in a Haystack과 비슷하게 Synthetic한 벤치마크이지만 과제를 좀 더 다양하고 까다롭게 만들었군요. 물론 이 벤치마크에 대한 스코어가 실제 과제에서의 성능과 어떻게 연관되는지가 중요한 문제이긴 하겠죠.
#benchmark
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
(Yu Ying Chiu, Liwei Jiang, Maria Antoniak, Chan Young Park, Shuyue Stella Li, Mehar Bhatia, Sahithya Ravi, Yulia Tsvetkov, Vered Shwartz, Yejin Choi)

Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
LLM의 도움을 받아 문화적 레드 티밍을 위한 데이터셋을 구축하는 도구. 사용자가 아이디어를 내면 그에 대해 LLM이 문제 작성에 도움을 주거나 피드백을 주고, 작성한 문제에 대한 LLM의 성능을 검증하면서 문제의 난이도를 높여나가는 방식이네요.
#dataset