



2024년 3월 29일

Qwen1.5-MoE
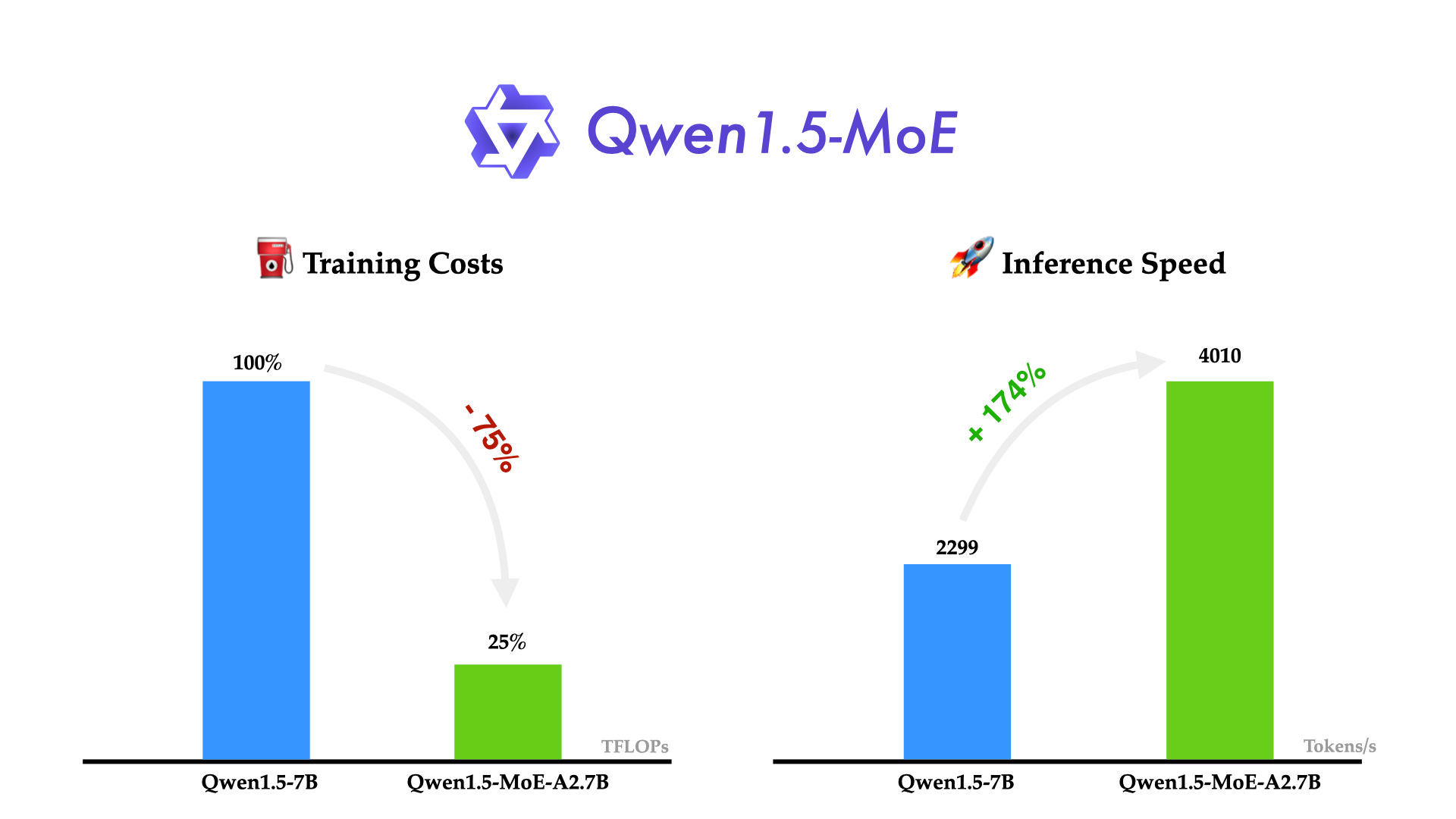
Qwen의 MoE 모델이 나왔군요. 2.7 Activated Parameter에 14.3 Total Parameter 모델입니다.
1.8B 모델을 Upcycling한 모델인데 초기화 과정에서 노이즈를 추가했다고 하는군요. (정확히 어떻게 한 것인지는 나와있지 않습니다.) 그리고 FFN을 그대로 복붙하는 것이 아니라 쪼갰습니다. 4개로 쪼갠 다음 16번 복붙해서 64개의 Expert를 만든 것 같군요.
그리고 4개의 Expert는 Shared Expert로 사용해서 늘 Activate 되게 만들고 나머지 60개 Expert에서 Top-4를 사용하는 방식입니다. DeepSeekMoE (https://arxiv.org/abs/2401.06066) 와 유사한 아이디어입니다.
#llm #moe
Jamba

Mixtral과 비슷한 규모의 SSM (Mamba) + Attention 하이브리드 & MoE를 사용한 모델이 벌써 등장했군요. 하이브리드 모델의 잠재력이 어느 정도일지 궁금했는데 그렇게 작지 않은 모델이 등장했으니 이 모델을 찔러보면 단서를 얻을 수 있을 듯 싶습니다.
#state-space-model #llm