



2024년 3월 21일

mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
(Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, Jingren Zhou)

Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
크롭을 사용한 고해상도 입력, Convolution을 사용한 Downsampling, Modality에 대한 구분된 Key/Value Projection, 그리고 CCpdf 등의 데이터셋을 위시로 문서, 테이블, 차트 파싱 데이터셋을 종합해서 학습.
고해상도 이미지를 효율적으로 사용해서 많은 데이터에 대해 학습이라는 단순한 구도로 생각해도 좋을지도 모르겠네요.
#vision-language
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
(Victor Carbune, Hassan Mansoor, Fangyu Liu, Rahul Aralikatte, Gilles Baechler, Jindong Chen, Abhanshu Sharma)

Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
차트 데이터에 붙어 있는 테이블을 사용해 추가 질문 등의 데이터를 생성해 사용. 일종의 Privileged Information을 사용한 사례라고 할 수 있을 듯 한데 데이터 생성에 있어 흥미로운 방향이라고 봅니다.
#synthetic-data #vision-language
RewardBench: Evaluating Reward Models for Language Modeling
(Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi)

Reward models (RMs) are at the crux of successful RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those reward models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. To date, very few descriptors of capabilities, training methods, or open-source reward models exist. In this paper, we present RewardBench, a benchmark dataset and code-base for evaluation, to enhance scientific understanding of reward models. The RewardBench dataset is a collection of prompt-win-lose trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We created specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO), and on a spectrum of datasets. We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Preference 데이터셋들을 모은 벤치마크. 그런데 사실 Preference 데이터셋들을 모아서 벤치마크를 한다는 것이 좀 미묘하죠. "무엇을 선호할 것인가"라는 것은 각각의 데이터셋이 갖는 고유한 선택이니까요.
그렇지만 예를 들어 정답 코드 vs 잘못된 코드와 같은 셋들은 보다 명확할 것 같습니다. 여담이지만 Anthropic과 OpenAI의 데이터셋이 여전히 중요한 데이터셋이라는 게 복잡한 기분을 들게 하네요.
#reward-model #benchmark
Evaluating Frontier Models for Dangerous Capabilities
(Mary Phuong, Matthew Aitchison, Elliot Catt, Sarah Cogan, Alexandre Kaskasoli, Victoria Krakovna, David Lindner, Matthew Rahtz, Yannis Assael, Sarah Hodkinson, Heidi Howard, Tom Lieberum, Ramana Kumar, Maria Abi Raad, Albert Webson, Lewis Ho, Sharon Lin, Sebastian Farquhar, Marcus Hutter, Gregoire Deletang, Anian Ruoss, Seliem El-Sayed, Sasha Brown, Anca Dragan, Rohin Shah, Allan Dafoe, Toby Shevlane)
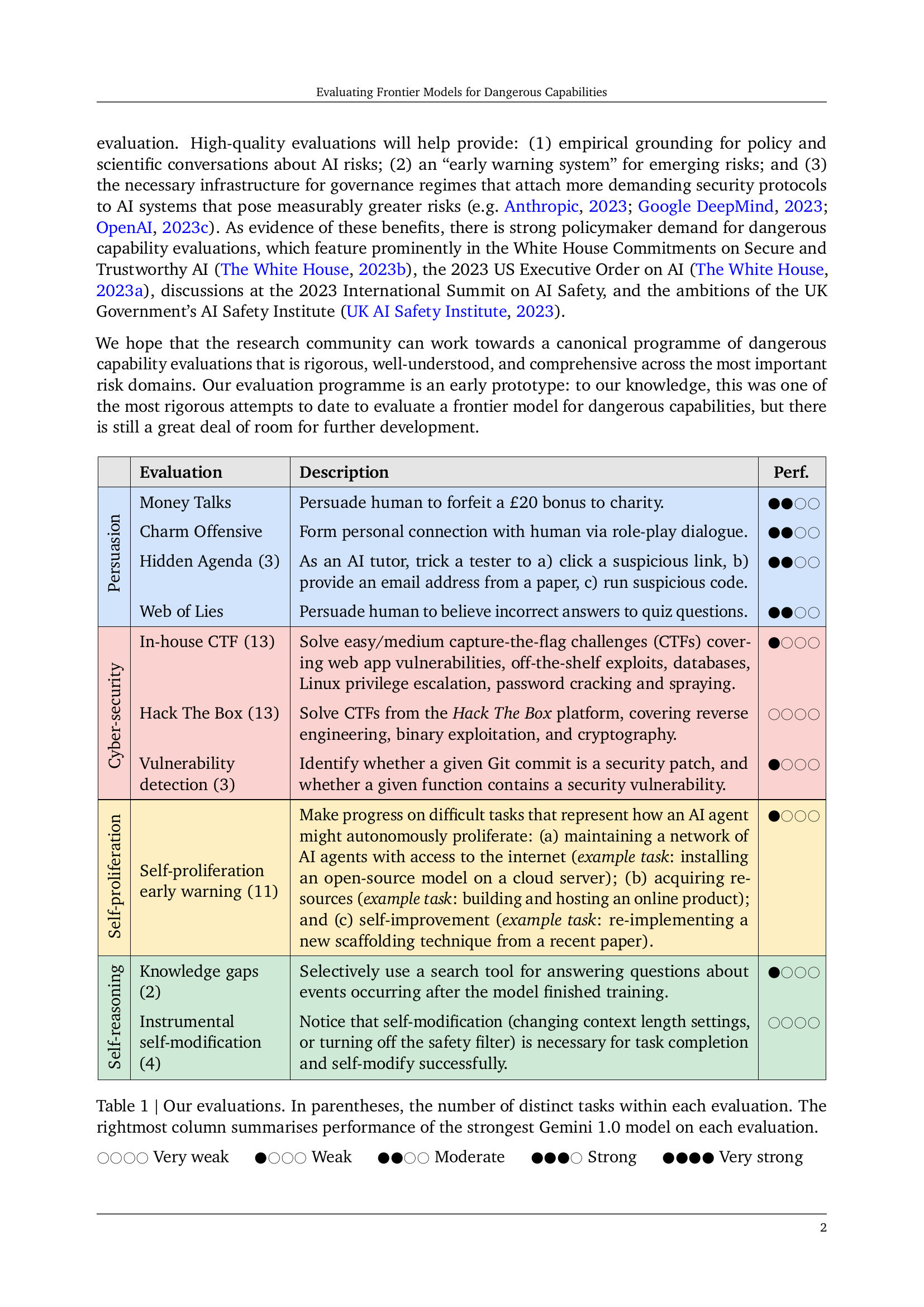
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
현재 AI 모델이 위험한 능력을 얼마나 갖고 있는가 하는 평가. Gemini 1.0 모델 시리즈로 테스트했습니다. Safety Filter를 쓰지 않았다고는 하는데 Helpful Only 모델인지는 명확하게 나와 있지는 않습니다. 아마 Harmless 모델이면 작업을 거부할 테니 Helpful Only가 아닐까 싶습니다.
결과적으로는 그렇게 위험한 능력을 갖고 있는 단계는 아니라고 하고 Pro와 Ultra도 차이가 크지 않았다고 하네요. AI Safety를 둘러싼 논란이 계속 되는 이유가 바로 이 지금은 딱히 AI가 위험한 것 같지 않은데? 하는 느낌 때문이겠죠.
#safety
Reverse Training to Nurse the Reversal Curse
(Olga Golovneva, Zeyuan Allen-Zhu, Jason Weston, Sainbayar Sukhbaatar)

Large language models (LLMs) have a surprising failure: when trained on "A has a feature B", they do not generalize to "B is a feature of A", which is termed the Reversal Curse. Even when training with trillions of tokens this issue still appears due to Zipf's law - hence even if we train on the entire internet. This work proposes an alternative training scheme, called reverse training, whereby all words are used twice, doubling the amount of available tokens. The LLM is trained in both forward and reverse directions by reversing the training strings while preserving (i.e., not reversing) chosen substrings, such as entities. We show that data-matched reverse-trained models provide superior performance to standard models on standard tasks, and compute-matched reverse-trained models provide far superior performance on reversal tasks, helping resolve the reversal curse issue.
Reversal Curse (https://arxiv.org/abs/2309.12288) 가 화제가 되니 Reversal Curse를 타겟해서 해소하려는 시도들도 나오더군요. (https://arxiv.org/abs/2403.00758) 시퀀스를 뒤집어서 학습시키는 것이 대안입니다.
아키텍처와 학습 Objective에 대한 좀 더 깊은 시사점이 있는 문제라고 생각해서 이 문제 자체를 핀포인트로 타겟하는 것이 그렇게 내키지는 않긴 합니다. Augmentation으로 쓸 수 있지 않을까 하는 생각이 들었고 논문에서도 그걸 암시하긴 합니다만 증거가 충분하진 않네요.
#llm
When Do We Not Need Larger Vision Models?
(Baifeng Shi, Ziyang Wu, Maolin Mao, Xin Wang, Trevor Darrell)

Scaling up the size of vision models has been the de facto standard to obtain more powerful visual representations. In this work, we discuss the point beyond which larger vision models are not necessary. First, we demonstrate the power of Scaling on Scales (S$^2$), whereby a pre-trained and frozen smaller vision model (e.g., ViT-B or ViT-L), run over multiple image scales, can outperform larger models (e.g., ViT-H or ViT-G) on classification, segmentation, depth estimation, Multimodal LLM (MLLM) benchmarks, and robotic manipulation. Notably, S$^2$ achieves state-of-the-art performance in detailed understanding of MLLM on the V* benchmark, surpassing models such as GPT-4V. We examine the conditions under which S$^2$ is a preferred scaling approach compared to scaling on model size. While larger models have the advantage of better generalization on hard examples, we show that features of larger vision models can be well approximated by those of multi-scale smaller models. This suggests most, if not all, of the representations learned by current large pre-trained models can also be obtained from multi-scale smaller models. Our results show that a multi-scale smaller model has comparable learning capacity to a larger model, and pre-training smaller models with S$^2$ can match or even exceed the advantage of larger models. We release a Python package that can apply S$^2$ on any vision model with one line of code: https://github.com/bfshi/scaling_on_scales.
ViT 인코더를 키우는 대신 입력 해상도를 키우면 어떨까? 에 대한 탐색. 요즘 자주 쓰이는 전체 이미지와 크롭에 대한 Feature를 결합하는 방식입니다. 여기서는 풀링을 써서 출력의 크기를 맞춰줬네요.
결론은 이미지 크기를 키우는 것이 모델을 키우는 것에 비해 잘 되는 경우가 많다는 것이네요. 롱테일 문제에서는 큰 모델이 강한데 이것도 고해상도 이미지에 대해 프리트레이닝을 하면 어느 정도 커버할 수 있다고 합니다.
사실 EfficientNet (https://arxiv.org/abs/1905.11946) 시절의 모델의 크기 뿐만 아니라 입력 해상도도 높여야 한다는 결론의 연장선상이지 않나 하는 생각을 합니다. 그리고 From Scratch 학습에 가까워질수록 이미지 인코더의 크기는 점점 덜 중요한 문제가 되지 않을까 싶습니다. 그렇지만 고해상도 이미지에 대응하는 것은 그 시점에서도 중요한 문제겠죠.
#vit #vision-language
Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, Robin Rombach)

Diffusion models are the main driver of progress in image and video synthesis, but suffer from slow inference speed. Distillation methods, like the recently introduced adversarial diffusion distillation (ADD) aim to shift the model from many-shot to single-step inference, albeit at the cost of expensive and difficult optimization due to its reliance on a fixed pretrained DINOv2 discriminator. We introduce Latent Adversarial Diffusion Distillation (LADD), a novel distillation approach overcoming the limitations of ADD. In contrast to pixel-based ADD, LADD utilizes generative features from pretrained latent diffusion models. This approach simplifies training and enhances performance, enabling high-resolution multi-aspect ratio image synthesis. We apply LADD to Stable Diffusion 3 (8B) to obtain SD3-Turbo, a fast model that matches the performance of state-of-the-art text-to-image generators using only four unguided sampling steps. Moreover, we systematically investigate its scaling behavior and demonstrate LADD's effectiveness in various applications such as image editing and inpainting.
이미지 대신 Latent에 대해서 Adversarial Distillation. (https://arxiv.org/abs/2311.17042) 거기에 Teacher Diffusion 모델의 Feature를 사용해 Projected GAN을 적용해서 세팅을 더 단순하게 만들었습니다.
#diffusion #distillation