



2024년 3월 14일

Scaling Instructable Agents Across Many Simulated Worlds

3D 게임/환경에 대한 에이전트. 언어로 지시하면 그에 따라 키보드와 마우스 조작으로 3D 환경에서 과제를 수행하는 형태입니다. 게임과 3D 환경을 준비하고 혹은 구축한 다음 이에 대해 Behavioral Cloning을 하기 위한 데이터를 구축했군요. 단적으로 사람의 플레이와 그에 대한 지시 데이터를 구축했습니다.
에이전트 구축을 위해서 프리트레이닝된 모델들을 조합했는데 이쪽도 좀 재미있네요. 영상 예측을 위해 Phenaki (https://arxiv.org/abs/2210.02399), 이미지-텍스트에 대해 SPARC (https://arxiv.org/abs/2401.09865) 이를 결합하는 Transformer에 더불어 과거 메모리를 모델링하는 Transformer-XL이 사용됐군요. Transformer-XL은 정말 오랜만에 보네요.
이 위에 Policy 모델을 올려서 키보드/마우스 조작을 예측하게 했습니다. 여기에 Classifier Free Guidance를 사용해서 언어 입력에 대한 Conditioning을 강화했군요.
#agent
Claude 3 Haiku
Claude 3 Haiku가 배포됐군요. GPT-3.5보다 고성능이면서 더 저렴하다고 하고 있습니다. 고성능/고비용 모델 뿐만 아니라 적당한 성능에 저렴한 모델에 대한 수요는 지속적으로 있을 것이고 그걸 타겟하는 것도 중요한 문제일 듯 하네요. 더하자면 파인튜닝으로 특화한 더 저렴한 모델들 또한 수요가 있겠죠.
#llm
Maximizing training throughput using PyTorch FSDP
FSDP로 프리트레이닝 수준의 학습을 진행해보려는 노력은 계속되네요. OLMo도 그랬고 이번에는 IBM 쪽이네요. Computation/Communication Overlap은 기본적으로 중요한 문제였고 여기서 추가적으로 소개하는 것은 Activation Checkpointing을 몇 개 레이어 당 한 번으로 줄여 속도를 개선하려는 시도군요.
Tensor Parallel이나 Sequence Parallel과 결합해서 좀 더 향상시킬 수 있는 방향이 있지 않을까 싶긴 합니다. 그렇지만 거기까지 하면 3D Parallel로 가는 것이 맞지 않을까 하는 생각을 하게될 것 같긴 하네요.
#efficient-training
Language models scale reliably with over-training and on downstream tasks
(Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Alexandros G. Dimakis, Gabriel Ilharco, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt)
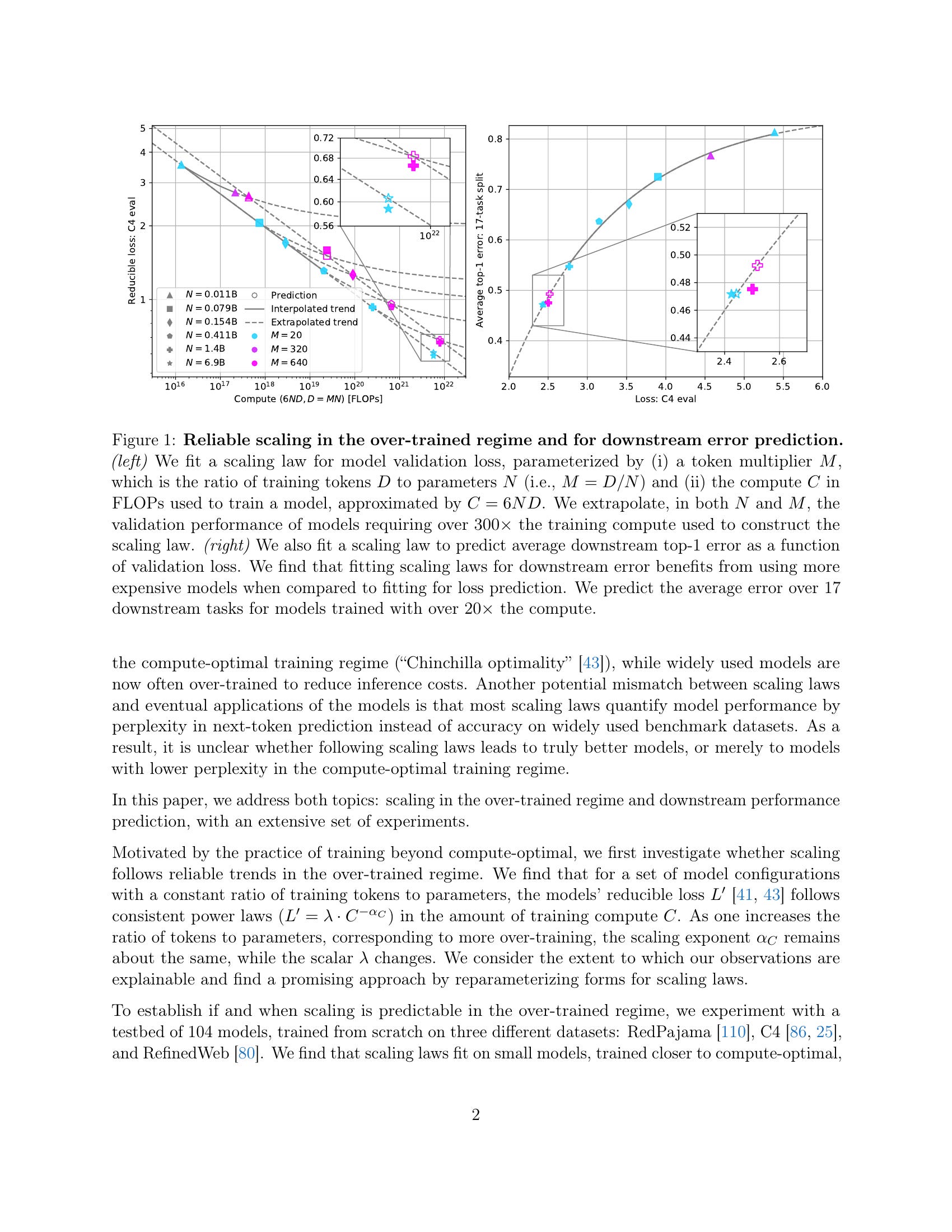
Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32× over-trained) and a 6.9B parameter, 138B token run—each from experiments that take 300× less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20× less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Chinchilla Optimal을 넘어선 Overtraining에 대한 Scaling Law와 Perplexity와 Downstream Task 성능에 대한 Scaling Law. 여기서의 가정은 Token Multiplier 즉 학습 토큰 D / 모델 크기 N의 변동에 대해 Scaling Curve는 경사의 변동 없이 평행 이동 한다는 것입니다. 사실 Chinchilla의 Parametric Loss의 형태에서 나오는 결과이긴 하죠.
저는 처음 봤을 때 상호작용이 있어야 하지 않을까 하는 생각을 했었는데 여전히 잘 들어맞네요.
#scaling-law
Simple and Scalable Strategies to Continually Pre-train Large Language Models
(Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L. Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, Irina Rish)

Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by final loss and language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Continual Pretraining에 대한 세팅 탐색. 이전 트레이닝 스케줄 때와 같은 수준의 LR로 LR Warmup, LR Decay, 이전 트레이닝 데이터를 5% 정도 섞기가 발견한 레시피군요. Infinite LR 스케줄이 편리하지 않을까 하는 이야기도 하고 있습니다. 추가 프리트레이닝을 해야할 경우가 빈번하다는 경험 때문인지 중국 쪽에서는 요새 Infinite LR 스케줄이 인기 있죠.
#continual-learning
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
(Renjie Pi, Tianyang Han, Wei Xiong, Jipeng Zhang, Runtao Liu, Rui Pan, Tong Zhang)

Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a "preference" for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
이미지-텍스트 Alignment는 텍스트 프리트레이닝에 비해 규모가 작기에 Vision-Language 모델은 여전히 텍스트 프리트레이닝의 영향을 크게 받고 있고 따라서 이미지에 제대로 Grounding 되어 있지 않고 대신 텍스트적인 특성에 따라 생성하는 경향이 많다는 아이디어.
대응 방안은 Golden Label을 Positive로 하고 이미지에 노이즈를 넣어 할루시네이션을 유도한 샘플들, LLM으로 텍스트를 변조한 샘플들을 Negative로 설정해서 DPO를 했습니다.
결국 RL을 하자는 결론이 다시 나왔군요.
#hallucination #rlaif