



2024년 2월 20일

LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
(Minsuk Kahng, Ian Tenney, Mahima Pushkarna, Michael Xieyang Liu, James Wexler, Emily Reif, Krystal Kallarackal, Minsuk Chang, Michael Terry, Lucas Dixon)

Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
두 LLM에 대한 비교 평가를 분석하기 위한 인터페이스. 카테고리나 판단 근거 같은 것들이 아무래도 주축이 되는군요. 최근 Preference 분류 성향에 대한 클러스터링 등으로 데이터에 대한 이해를 높일 수 있으리라는 생각을 해봤었는데 여러모로 생각해 볼만한 부분이 있지 않을까 싶습니다.
#evaluation #tool
When is Tree Search Useful for LLM Planning? It Depends on the Discriminator
(Ziru Chen, Michael White, Raymond Mooney, Ali Payani, Yu Su, Huan Sun)
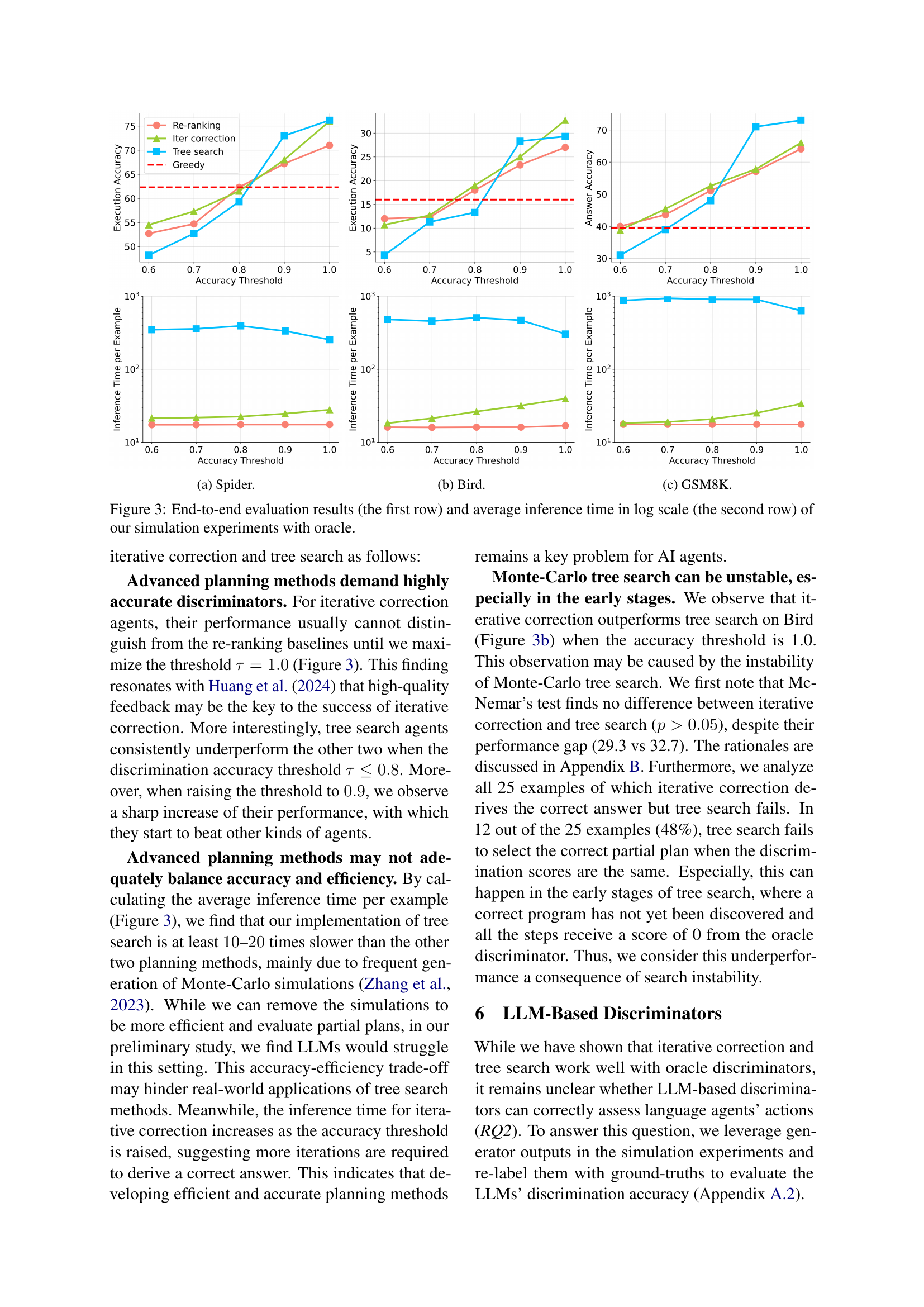
In this paper, we examine how large language models (LLMs) solve multi-step problems under a language agent framework with three components: a generator, a discriminator, and a planning method. We investigate the practical utility of two advanced planning methods, iterative correction and tree search. We present a comprehensive analysis of how discrimination accuracy affects the overall performance of agents when using these two methods or a simpler method, re-ranking. Experiments on two tasks, text-to-SQL parsing and mathematical reasoning, show that: (1) advanced planning methods demand discriminators with at least 90% accuracy to achieve significant improvements over re-ranking; (2) current LLMs' discrimination abilities have not met the needs of advanced planning methods to achieve such improvements; (3) with LLM-based discriminators, advanced planning methods may not adequately balance accuracy and efficiency. For example, compared to the other two methods, tree search is at least 10--20 times slower but leads to negligible performance gains, which hinders its real-world applications. Code and data will be released at https://github.com/OSU-NLP-Group/llm-planning-eval.
LLM의 응답을 서치할 때 응답을 평가하는 Discriminator의 성능이 결과에 미치는 영향. Text2SQL과 GSM8K에 대해 테스트했는데 Greedy하게 샘플링하는 것보다 나은 성능을 보이려면 Discriminator의 성능이 80 - 90% 이상이 되어야 하고, 트리 서치 같은 보다 복잡한 방법은 성능 요구치가 더 높다는 발견입니다.
서치 알고리즘 자체보다도 탐색의 기준이 되는 피드백을 어떻게 설정할 것인가가 당연하게도 더 어려운 문제겠죠. 정확한 피드백을 얻기 쉬운 문제로 국한하자면 범위가 좁고요.
#search
Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning
(Zhiyang Xu, Chao Feng, Rulin Shao, Trevor Ashby, Ying Shen, Di Jin, Yu Cheng, Qifan Wang, Lifu Huang)

Despite vision-language models' (VLMs) remarkable capabilities as versatile visual assistants, two substantial challenges persist within the existing VLM frameworks: (1) lacking task diversity in pretraining and visual instruction tuning, and (2) annotation error and bias in GPT-4 synthesized instruction tuning data. Both challenges lead to issues such as poor generalizability, hallucination, and catastrophic forgetting. To address these challenges, we construct Vision-Flan, the most diverse publicly available visual instruction tuning dataset to date, comprising 187 diverse tasks and 1,664,261 instances sourced from academic datasets, and each task is accompanied by an expert-written instruction. In addition, we propose a two-stage instruction tuning framework, in which VLMs are firstly finetuned on Vision-Flan and further tuned on GPT-4 synthesized data. We find this two-stage tuning framework significantly outperforms the traditional single-stage visual instruction tuning framework and achieves the state-of-the-art performance across a wide range of multi-modal evaluation benchmarks. Finally, we conduct in-depth analyses to understand visual instruction tuning and our findings reveal that: (1) GPT-4 synthesized data does not substantially enhance VLMs' capabilities but rather modulates the model's responses to human-preferred formats; (2) A minimal quantity (e.g., 1,000) of GPT-4 synthesized data can effectively align VLM responses with human-preference; (3) Visual instruction tuning mainly helps large-language models (LLMs) to understand visual features.
비전 데이터셋들을 모아 FLAN 스타일의 Instruction 데이터셋을 구축했군요. 논문에서 제안하고 있는 것처럼 중간 단계 튜닝으로 (어쩌면 프리트레이닝에 포함시킬 수도 있겠죠) 사용할 수 있을 듯 싶습니다.
#instruction-tuning #dataset #vision-language
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
(Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, Beidi Chen)

As the usage of large language models (LLMs) grows, performing efficient inference with these models becomes increasingly important. While speculative decoding has recently emerged as a promising direction for speeding up inference, existing methods are limited in their ability to scale to larger speculation budgets, and adapt to different hyperparameters and hardware. This paper introduces Sequoia, a scalable, robust, and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to 4.04×4.04×, 3.84×3.84×, and 2.37×2.37×, and Llama2-70B offloading by up to 10.33×10.33× on L40.
Speculative Decoding에서 후보 시퀀스를 하나 뽑는 것이 아니라 토큰들의 트리를 구성하는 방법. 여기서 Top-K 토큰으로 확장하는 것이 아니라 Verification을 통과할 토큰을 최대화하는 방식으로 트리를 구성한다는 것이 주 아이디어입니다.
#efficiency
A Critical Evaluation of AI Feedback for Aligning Large Language Models
(Archit Sharma, Sedrick Keh, Eric Mitchell, Chelsea Finn, Kushal Arora, Thomas Kollar)
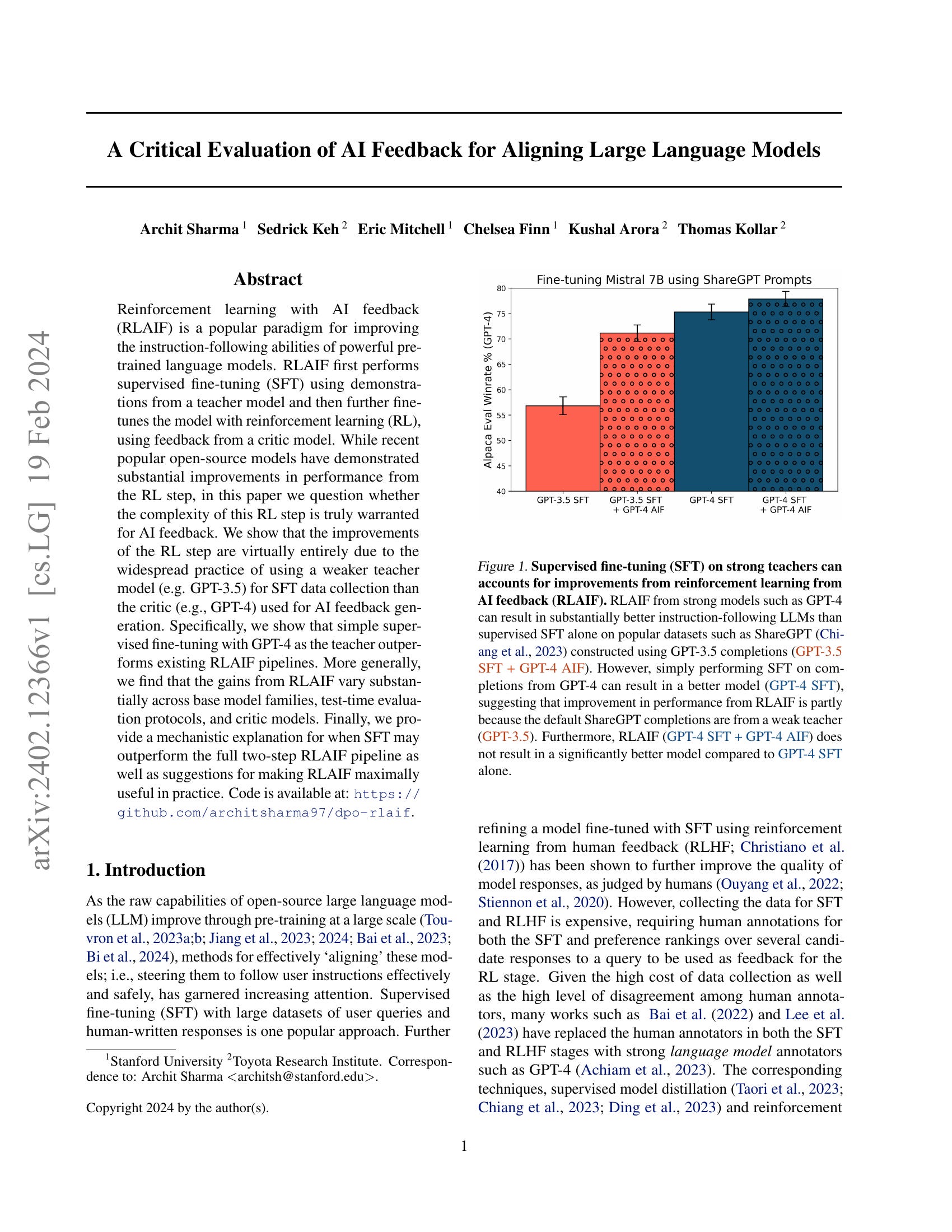
Reinforcement learning with AI feedback (RLAIF) is a popular paradigm for improving the instruction-following abilities of powerful pre-trained language models. RLAIF first performs supervised fine-tuning (SFT) using demonstrations from a teacher model and then further fine-tunes the model with reinforcement learning (RL), using feedback from a critic model. While recent popular open-source models have demonstrated substantial improvements in performance from the RL step, in this paper we question whether the complexity of this RL step is truly warranted for AI feedback. We show that the improvements of the RL step are virtually entirely due to the widespread practice of using a weaker teacher model (e.g. GPT-3.5) for SFT data collection than the critic (e.g., GPT-4) used for AI feedback generation. Specifically, we show that simple supervised fine-tuning with GPT-4 as the teacher outperforms existing RLAIF pipelines. More generally, we find that the gains from RLAIF vary substantially across base model families, test-time evaluation protocols, and critic models. Finally, we provide a mechanistic explanation for when SFT may outperform the full two-step RLAIF pipeline as well as suggestions for making RLAIF maximally useful in practice.
GPT-4로 Preference Feedback을 주는 것의 효과는 SFT 과정에서 3.5 데이터를 썼기 때문이 아닐까 하는 분석. Preference Feedback을 주는 대신 GPT-4의 샘플로 SFT를 하면 성능이 비슷하더라는 결과입니다.
논의 부분에서 RLHF가 성공적인 것은 사람을 통한 SFT 데이터셋과 Preference 데이터셋의 구축 난이도의 차이 때문이고 GPT-4로 생성한 샘플을 쓴다면 비용적으로는 오히려 Preference 데이터가 비싸니 Preference 데이터를 사용하는 튜닝은 불필요한 것이 아닐까...하는 이야기를 하고 있네요.
전 그런 의미에서 RLHF에 집중하거나 혹은 RLHF된 모델의 샘플을 사용하는 것이 아닌 프리트레이닝된 LM에서 시작하는 RLAIF 방향의 탐색이 흥미로운 길이 아닌가 하는 생각이 있습니다. 물론 UltraFeedback처럼 GPT-4로 Preference 데이터를 더 잘 추출한다면 성능 개선이 있을 수 있겠지만요.
#rlhf #rlaif
FiT: Flexible Vision Transformer for Diffusion Model
(Zeyu Lu, Zidong Wang, Di Huang, Chengyue Wu, Xihui Liu, Wanli Ouyang, Lei Bai)

Nature is infinitely resolution-free. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To overcome this limitation, we present the Flexible Vision Transformer (FiT), a transformer architecture specifically designed for generating images with unrestricted resolutions and aspect ratios. Unlike traditional methods that perceive images as static-resolution grids, FiT conceptualizes images as sequences of dynamically-sized tokens. This perspective enables a flexible training strategy that effortlessly adapts to diverse aspect ratios during both training and inference phases, thus promoting resolution generalization and eliminating biases induced by image cropping. Enhanced by a meticulously adjusted network structure and the integration of training-free extrapolation techniques, FiT exhibits remarkable flexibility in resolution extrapolation generation. Comprehensive experiments demonstrate the exceptional performance of FiT across a broad range of resolutions, showcasing its effectiveness both within and beyond its training resolution distribution. Repository available at https://github.com/whlzy/FiT.
2D RoPE, 임의 Aspect Ratio를 Diffusion Transformer에 적용해본 실험. 최대 길이 패딩을 사용한 방법입니다. 2D RoPE와 Sequence Packing을 사용하는 방법을 Unified-IO 2 (https://arxiv.org/abs/2312.17172) 에서 채택했는데 같이 보는 것도 재미있을 것 같네요. Sora의 디테일을 상상해보려면 특히.
#diffusion #transformer