



2024년 2월 13일

Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
(Shivalika Singh, Freddie Vargus, Daniel Dsouza, Börje F. Karlsson, Abinaya Mahendiran, Wei-Yin Ko, Herumb Shandilya, Jay Patel, Deividas Mataciunas, Laura OMahony, Mike Zhang, Ramith Hettiarachchi, Joseph Wilson, Marina Machado, Luisa Souza Moura, Dominik Krzemiński, Hakimeh Fadaei, Irem Ergün, Ifeoma Okoh, Aisha Alaagib, Oshan Mudannayake, Zaid Alyafeai, Vu Minh Chien, Sebastian Ruder, Surya Guthikonda, Emad A. Alghamdi, Sebastian Gehrmann, Niklas Muennighoff, Max Bartolo, Julia Kreutzer, Ahmet Üstün, Marzieh Fadaee, Sara Hooker)

Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.
다국어 Instruction 데이터셋. 작업자가 직접 작성하는 방식으로 구축된 Aya Dataset과 이에 더해 템플릿과 기계 번역으로 구축한 데이터셋으로 구성된 Aya Collection이 있습니다. 아직 데이터셋이 배포되지는 않은 것 같은데 퀄리티가 궁금하네요.
#multilingual #instruction #dataset
V-STaR: Training Verifiers for Self-Taught Reasoners
(Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, Rishabh Agarwal)

Common self-improvement approaches for large language models (LLMs), such as STaR (Zelikman et al., 2022), iteratively fine-tune LLMs on self-generated solutions to improve their problem-solving ability. However, these approaches discard the large amounts of incorrect solutions generated during this process, potentially neglecting valuable information in such solutions. To address this shortcoming, we propose V-STaR that utilizes both the correct and incorrect solutions generated during the self-improvement process to train a verifier using DPO that judges correctness of model-generated solutions. This verifier is used at inference time to select one solution among many candidate solutions. Running V-STaR for multiple iterations results in progressively better reasoners and verifiers, delivering a 4% to 17% test accuracy improvement over existing self-improvement and verification approaches on common code generation and math reasoning benchmarks with LLaMA2 models.
샘플링 -> 레이블링 -> 정답만 모아 다시 SFT라는 루프에서 오답을 따로 모은 다음 정답과 오답으로 DPO를 해서 Verifier를 추가로 학습하는 방법. 그리고 테스트 시점에서 Verifier를 사용해서 샘플을 필터링합니다. 학습 도메인에 대한 성능 향상과 GSM8K -> MATH, MBPP -> HumanEval로의 Transfer을 보여주고 있네요.
#synthetic-data
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
(Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, Honglin Guo, Wei Shen, Xiaoran Fan, Yuhao Zhou, Shihan Dou, Xiao Wang, Xinbo Zhang, Peng Sun, Tao Gui, Qi Zhang, Xuanjing Huang)

In this paper, we propose R$^3$: Learning Reasoning through Reverse Curriculum Reinforcement Learning (RL), a novel method that employs only outcome supervision to achieve the benefits of process supervision for large language models. The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision provides sparse rewards for final results without identifying error locations, whereas process supervision offers step-wise rewards but requires extensive manual annotation. R$^3$ overcomes these limitations by learning from correct demonstrations. Specifically, R$^3$ progressively slides the start state of reasoning from a demonstration's end to its beginning, facilitating easier model exploration at all stages. Thus, R$^3$ establishes a step-wise curriculum, allowing outcome supervision to offer step-level signals and precisely pinpoint errors. Using Llama2-7B, our method surpasses RL baseline on eight reasoning tasks by 4.14.1 points on average. Notebaly, in program-based reasoning on GSM8K, it exceeds the baseline by 4.24.2 points across three backbone models, and without any extra data, Codellama-7B + R$^3$ performs comparable to larger models or closed-source models.
Outcome supervision의 저렴하지만 학습 시그널이 줄어드는 문제, Process supervision의 학습 시그널이 늘어나지만 데이터 구축 비용이 높아지는 문제를 절충하려고 시도한 방법.
기본적으로 Golden reasoning chain 데이터가 있다고 가정하고 시작합니다. Reasoning chain을 나눠서 마지막 스텝만 예측하기, 끝에서 두 개 스텝을 예측하기 등등으로 전체를 예측하는 것이 아니라 일부만 예측하게 하는 방법으로 가이드를 준다고 할 수 있겠네요.
#reward-model
Multilingual E5 Text Embeddings: A Technical Report
(Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei)

This technical report presents the training methodology and evaluation results of the open-source multilingual E5 text embedding models, released in mid-2023. Three embedding models of different sizes (small / base / large) are provided, offering a balance between the inference efficiency and embedding quality. The training procedure adheres to the English E5 model recipe, involving contrastive pre-training on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets. Additionally, we introduce a new instruction-tuned embedding model, whose performance is on par with state-of-the-art, English-only models of similar sizes. Information regarding the model release can be found at https://github.com/microsoft/unilm/tree/master/e5 .
E5 + 생성 데이터 (https://arxiv.org/abs/2401.00368) 추가로 구축한 다국어 E5. LLM과 함께 좋은 Retriever도 중요한 시점이죠.
#retrieval
Hydragen: High-Throughput LLM Inference with Shared Prefixes
(Jordan Juravsky, Bradley Brown, Ryan Ehrlich, Daniel Y. Fu, Christopher Ré, Azalia Mirhoseini)
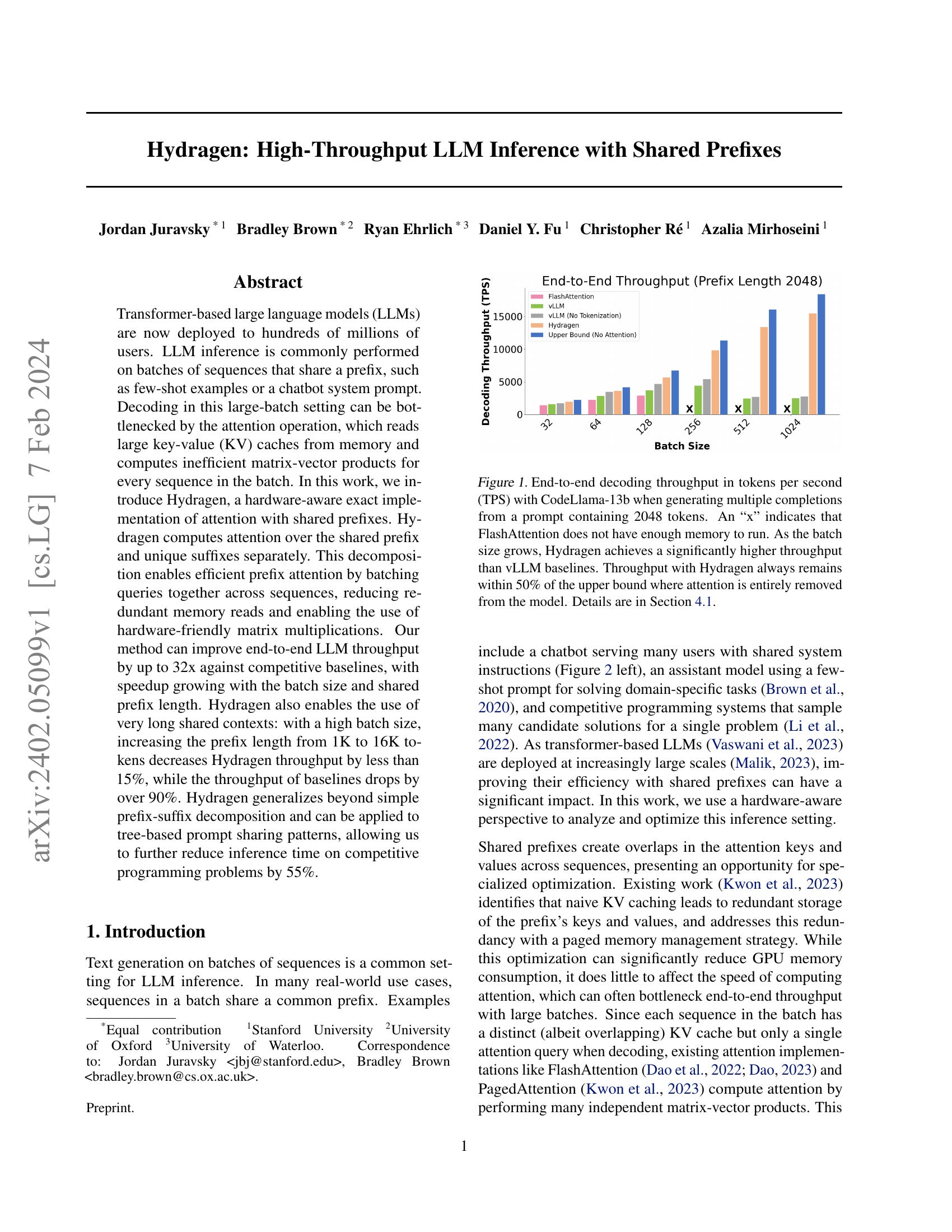
Transformer-based large language models (LLMs) are now deployed to hundreds of millions of users. LLM inference is commonly performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. In this work, we introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications. Our method can improve end-to-end LLM throughput by up to 32x against competitive baselines, with speedup growing with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a high batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.
Prefix, 즉 입력의 앞 부분을 공유하는 경우에 대해서 LLM 추론 속도를 향상시키기 위한 방법. vLLM이나 Radix Attention의 최적화에 더해 Attention 계산 자체에서 중복을 제거하는 것을 목표로 합니다.
#efficiency
Suppressing Pink Elephants with Direct Principle Feedback
(Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf, Siddharth Verma, Stella Biderman)

Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable \textit{at inference time}, so that they can be used in multiple contexts with diverse needs. We illustrate this with the \textbf{Pink Elephant Problem}: instructing an LLM to avoid discussing a certain entity (a
Pink Elephant''), and instead discuss a preferred entity (Grey Elephant''). We apply a novel simplification of Constitutional AI, \textbf{Direct Principle Feedback}, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.
코끼리는 생각하지 마, 즉 어떤 주제에 대해서 언급하지 말라는 금지 지시를 따르는 능력을 보완하려는 시도. 흥미로운 부분은 방법적으로 Constitutional AI의 RLAIF를 채택해서 생성된 응답에 대한 Critique와 Revision을 수행하는 형태로 접근했다는 것이네요. Constitutional AI에서 SFT와 Reward Modeling을 거친 것과는 다르게 여기서는 원 응답과 개선된 응답을 사용해 직접 DPO를 했습니다.
#alignment #rlaif
Scaling Laws for Fine-Grained Mixture of Experts
(Jakub Krajewski, Jan Ludziejewski, Kamil Adamczewski, Maciej Pióro, Michał Krutul, Szymon Antoniak, Kamil Ciebiera, Krystian Król, Tomasz Odrzygóźdź, Piotr Sankowski, Marek Cygan, Sebastian Jaszczur)

Mixture of Experts (MoE) models have emerged as a primary solution for reducing the computational cost of Large Language Models. In this work, we analyze their scaling properties, incorporating an expanded range of variables. Specifically, we introduce a new hyperparameter, granularity, whose adjustment enables precise control over the size of the experts. Building on this, we establish scaling laws for fine-grained MoE, taking into account the number of training tokens, model size, and granularity. Leveraging these laws, we derive the optimal training configuration for a given computational budget. Our findings not only show that MoE models consistently outperform dense Transformers but also highlight that the efficiency gap between dense and MoE models widens as we scale up the model size and training budget. Furthermore, we demonstrate that the common practice of setting the size of experts in MoE to mirror the feed-forward layer is not optimal at almost any computational budget.
MoE 모델에 대한 Scaling Law가 있었지만 (https://arxiv.org/abs/2202.01169) 이는 고정된 토큰에 대한 결과였죠. 여기서는 학습 토큰 수와 함께 Granularity, 즉 Expert의 히든 차원의 크기를 축소하는 요인까지 고려한 Scaling Law를 만들었습니다. DeepSeekMoE (https://arxiv.org/abs/2401.06066) 와 비슷한 세팅이라고 볼 수 있겠습니다.
Expert의 숫자 요인이 빠져 있고 실험의 규모가 좀 작다는 것이 아쉽기는 한데 선례도 있으니 MoE 디자인에서 고려할만한 부분이겠다 싶네요.
#moe #scaling-law
ODIN: Disentangled Reward Mitigates Hacking in RLHF
(Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Mohammad Shoeybi, Bryan Catanzaro)

In this work, we study the issue of reward hacking on the response length, a challenge emerging in Reinforcement Learning from Human Feedback (RLHF) on LLMs. A well-formatted, verbose but less helpful response from the LLMs can often deceive LLMs or even human evaluators to achieve high scores. The same issue also holds for some reward models in RL. To address the challenges in both training and evaluation, we establish a more reliable evaluation protocol for comparing different training configurations, which inspects the trade-off between LLM evaluation score and response length obtained by varying training hyperparameters. Based on this evaluation, we conduct large-scale studies, where the results shed insights into the efficacy of hyperparameters and tricks used in RL on mitigating length bias. We further propose to improve the reward model by jointly training two linear heads on shared feature representations to predict the rewards, one trained to correlate with length, and the other trained to decorrelate with length and therefore focus more on the actual content. We then discard the length head in RL to prevent reward hacking on length. Experiments demonstrate that our approach almost eliminates the reward correlation with length, and improves the obtained policy by a significant margin.
길이가 Reward Modeling에서 골치 아픈 문제다보니 직접적으로 길이 문제를 노리는 방법도 나오는군요. Reward Modeling 시점에 헤드를 두 개 만들어서 이 두 헤드의 조합으로 Loss를 계산하되, 길이 헤드의 경우 길이와 상관 관계를 높이고 퀄리티 헤드는 상관 관계를 낮추는 식으로, 또한 이 두 헤드가 직교하도록 해서 헤드를 Disentangle하는 방법입니다. PPO 시점에서는 퀄리티 헤드만 사용하죠.
#rlhf #reward-model
Debating with More Persuasive LLMs Leads to More Truthful Answers
(Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktäschel, Ethan Perez)

Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is \textit{debate}, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Weak-to-Strong Generalization 문제. 여기서의 특징은 능력이 아니라 정보의 측면에서 Weak와 Strong을 구분했다는 것이네요. Strong에서는 답에 대한 맥락 정보를 접근할 수 있고 Weak는 그 정보에 접근할 수 없습니다. 여기서의 제안 방법은 Strong 모델들이 논쟁을 하게 하고, 논쟁 과정에서 설득력이 높아지도록 했을 때 Weak 모델의 판단 정확도가 높아졌다는 결과입니다.
능력이 아니라 정보의 비대칭성을 고려하는 것이고, 인용 도구를 사용해서 Strong 모델이 텍스트를 직접 넘겨줄 수 있고 인용 텍스트를 검증할 수 있었다는 점에서 제한적이긴 합니다. 전문가들끼리 논쟁시킨 다음 더 설득력이 있는 것을 정답이라고 하면 맞을 가능성이 높을 것이다...라는 아이디어는 매력적이지만요.
#alignment
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
(Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh)

Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance −− a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization from language, and targeted challenge sets that probe properties such as hallucination; evaluations that provide calibrated, fine-grained insight into a VLM's capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and quantifying the tradeoffs of using base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible code for VLM training, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open-source VLMs.
VLM이 쏟아지는 중에 정리를 하고 가자는 제안. 통합된 평가 슈트와 학습 프레임워크를 만든 다음 이미지 처리, 이미지 인코더 앙상블, LM 등에 대해 비교 분석을 했습니다.
#vision-language #framework #evaluation
A Tale of Tails: Model Collapse as a Change of Scaling Laws
(Elvis Dohmatob, Yunzhen Feng, Pu Yang, Francois Charton, Julia Kempe)

As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning" of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
모델의 생성 데이터를 쓰는 것이 Scaling Law에 미칠 수 있는 문제. 생성 데이터는 필연적으로 데이터 분포의 꼬리를 잘라내게 되고, 이 꼬리가 잘려나가는 문제로 인해 Scaling Curve가 깨지고 Lower Bound가 생긴다는 분석.
분포의 꼬리가 잘려나간다는 것은 Scaling으로 인해 발생하는 새로운 능력에 제한이 걸릴 수 있다는 의미이고 이건 Scaling에 있어 아주 큰 문제가 되겠죠. 이 결과에 대한 함의에 대해서는 많이 생각해 봐야 할 것 같지만 일차적으로는 학습 분포에 대한 추가 샘플을 얻는 접근은 안 된다는 생각을 하게 되네요. 결국 Information Processing Inequality로 돌아가는 것 같긴 합니다만.
#synthetic-data #scaling-law
Understanding the Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation
(Xinyi Wang, Alfonso Amayuelas, Kexun Zhang, Liangming Pan, Wenhu Chen, William Yang Wang)

Pre-trained language models (LMs) are able to perform complex reasoning without explicit fine-tuning. To understand how pre-training with a next-token prediction objective contributes to the emergence of such reasoning capability, we propose that we can view an LM as deriving new conclusions by aggregating indirect reasoning paths seen at pre-training time. We found this perspective effective in two important cases of reasoning: logic reasoning with knowledge graphs (KGs) and math reasoning with math word problems (MWPs). More specifically, we formalize the reasoning paths as random walk paths on the knowledge/reasoning graphs. Analyses of learned LM distributions suggest that a weighted sum of relevant random walk path probabilities is a reasonable way to explain how LMs reason. Experiments and analysis on multiple KG and MWP datasets reveal the effect of training on random walk paths and suggest that augmenting unlabeled random walk reasoning paths can improve real-world multi-step reasoning performance.
LLM에서 추론 능력이 어떻게 발생하는가? 이 논문에서는 엔티티 노드들이 관계로 연결된 그래프를 생각합니다. 그리고 이 그래프 위에서 랜덤 워크를 통해 경유한 노드와 관계로 시퀀스를 만들어 학습 데이터를 만들죠.
그리고 이에 대해 LM 학습을 했을 때 엔티티들의 연결 경로들을 합쳐서 추론하는 알고리즘과 비슷하게 작동할 수 있다는 아이디어입니다.
#reasoning #lm