



2024년 12월 20일

FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
(Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen)

Autoregressive (AR) modeling has achieved remarkable success in natural language processing by enabling models to generate text with coherence and contextual understanding through next token prediction. Recently, in image generation, VAR proposes scale-wise autoregressive modeling, which extends the next token prediction to the next scale prediction, preserving the 2D structure of images. However, VAR encounters two primary challenges: (1) its complex and rigid scale design limits generalization in next scale prediction, and (2) the generator's dependence on a discrete tokenizer with the same complex scale structure restricts modularity and flexibility in updating the tokenizer. To address these limitations, we introduce FlowAR, a general next scale prediction method featuring a streamlined scale design, where each subsequent scale is simply double the previous one. This eliminates the need for VAR's intricate multi-scale residual tokenizer and enables the use of any off-the-shelf Variational AutoEncoder (VAE). Our simplified design enhances generalization in next scale prediction and facilitates the integration of Flow Matching for high-quality image synthesis. We validate the effectiveness of FlowAR on the challenging ImageNet-256 benchmark, demonstrating superior generation performance compared to previous methods. Codes will be available at https://github.com/OliverRensu/FlowAR.
VAR과 Diffusion 결합이 바로 또 나왔군요. (https://arxiv.org/abs/2412.14170)
Another study combining VAR and diffusion has just been released. (https://arxiv.org/abs/2412.14170)
#autoregressive-model #diffusion
Qwen2.5 Technical Report
(Qwen: An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zihan Qiu)
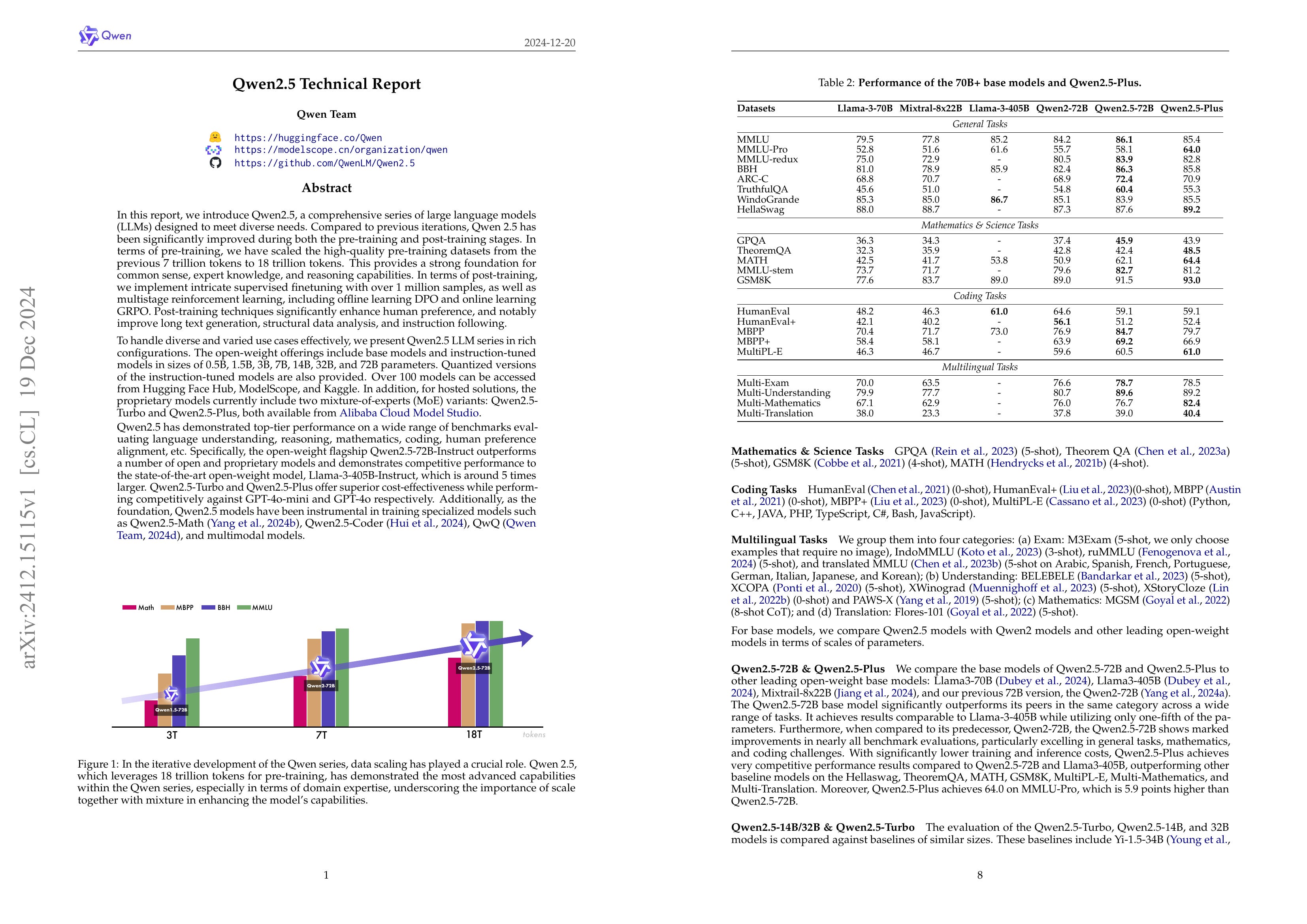
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Qwen 2.5 테크니컬 리포트. Qwen2.5-Math와 (https://arxiv.org/abs/2409.12122) Qwen2.5-Coder에서 (https://arxiv.org/abs/2409.12186) 소개된 데이터들 위에 학습. 하이퍼파라미터 Scaling Law를 사용했군요. 은근히 대세네요.
Qwen 2.5 Technical Report. This model was trained on the datasets introduced in Qwen2.5-Math (https://arxiv.org/abs/2409.12122) and Qwen2.5-Coder (https://arxiv.org/abs/2409.12186). They have utilized hyperparameter scaling laws. It seems to be quietly becoming a major trend.
#scaling-law #llm
How to Synthesize Text Data without Model Collapse?
(Xuekai Zhu, Daixuan Cheng, Hengli Li, Kaiyan Zhang, Ermo Hua, Xingtai Lv, Ning Ding, Zhouhan Lin, Zilong Zheng, Bowen Zhou)

Model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem. Future GPT-{𝑛}{n} models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse? We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance. We further conduct statistical analysis on synthetic data to uncover distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data. As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound. We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.
합성 데이터가 커버하는 분포의 범위가 좁다는 문제에 대한 분석. 이에 대한 대안으로 사람이 생성한 데이터에 대해 확률이 높은 토큰을 다른 토큰으로 교체하는 형태의 데이터 생성 방법을 제안했습니다.
합성 데이터를 사용할 것인가 자체보다는 어떻게 합성 데이터를 생성하는 것이 좋은가의 문제로 넘어가야 할 시점이네요.
This paper analyzes the problem of synthetic data having a narrow coverage of distribution. As an alternative, they propose a data generation method that replaces high-probability tokens in human-generated texts with other tokens.
I think it's time to move beyond the question of whether we should use synthetic data, and instead focus on how we can best generate it.
#synthetic-data
Outcome-Refining Process Supervision for Code Generation
(Zhuohao Yu, Weizheng Gu, Yidong Wang, Zhengran Zeng, Jindong Wang, Wei Ye, Shikun Zhang)

Large Language Models have demonstrated remarkable capabilities in code generation, yet they often struggle with complex programming tasks that require deep algorithmic reasoning. While process supervision through learned reward models shows promise in guiding reasoning steps, it requires expensive training data and suffers from unreliable evaluation. We propose Outcome-Refining Process Supervision, a novel paradigm that treats outcome refinement itself as the process to be supervised. Our framework leverages concrete execution signals to ground the supervision of reasoning steps, while using tree-structured exploration to maintain multiple solution trajectories simultaneously. Experiments demonstrate that our approach enables even smaller models to achieve high success accuracy and performance metrics on competitive programming tasks, creates more reliable verification than traditional reward models without requiring training PRMs. Our approach achieves significant improvements across 5 models and 3 datasets: an average of 26.9% increase in correctness and 42.2% in efficiency. The results suggest that providing structured reasoning space with concrete verification signals is crucial for solving complex programming tasks. We open-source all our code and data at: https://github.com/zhuohaoyu/ORPS
Execution 피드백과 Process Reward의 결합. 샘플링 후 생성된 코드를 실행하고 실행 결과에 대한 Critique을 생성해 피드백을 주는 구조군요.
Process Reward를 사용한다고 하더라도 각 스텝에 대한 점수를 주는 것을 넘어 그 스텝에 대한 추론 과정이 필요하다는 생각을 합니다. 그러면 PRM이 Critic 모델에 가까워지겠죠.
Combination of execution feedback and process reward. The structure involves executing the generated code after sampling and providing feedback through critiques of the execution results.
I believe that even when using process rewards, we need reasoning for each step beyond just scoring it. This would make the PRM more similar to critic models.
#reward-model #search #code
Jet: A Modern Transformer-Based Normalizing Flow
(Alexander Kolesnikov, André Susano Pinto, Michael Tschannen)

In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute log-likelihood of the input data, fast generation and simple overall structure. Normalizing flows remained a topic of active research but later fell out of favor, as visual quality of the samples was not competitive with other model classes, such as GANs, VQ-VAE-based approaches or diffusion models. In this paper we revisit the design of the coupling-based normalizing flow models by carefully ablating prior design choices and using computational blocks based on the Vision Transformer architecture, not convolutional neural networks. As a result, we achieve state-of-the-art quantitative and qualitative performance with a much simpler architecture. While the overall visual quality is still behind the current state-of-the-art models, we argue that strong normalizing flow models can help advancing research frontier by serving as building components of more powerful generative models.
구글도 Normalizing Flow 실험을 해봤군요. (https://arxiv.org/abs/2412.06329) 다른 어떤 요소 없이 Affine Coupling만으로도 충분하더라는 결과. (단 채널이 아닌 공간에 대해서도 분할하는 방법을 섞었네요.)
Google has also conducted experiments on normalizing flow. (https://arxiv.org/abs/2412.06329) The results show that affine coupling alone is sufficient without any other components. (However, they mixed splitting not only along the channels but also along the spatial dimensions.)
#flow
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
(Ziteng Wang, Jianfei Chen, Jun Zhu)

Sparsely activated Mixture-of-Experts (MoE) models are widely adopted to scale up model capacity without increasing the computation budget. However, vanilla TopK routers are trained in a discontinuous, non-differentiable way, limiting their performance and scalability. To address this issue, we propose ReMoE, a fully differentiable MoE architecture that offers a simple yet effective drop-in replacement for the conventional TopK+Softmax routing, utilizing ReLU as the router instead. We further propose methods to regulate the router's sparsity while balancing the load among experts. ReMoE's continuous nature enables efficient dynamic allocation of computation across tokens and layers, while also exhibiting domain specialization. Our experiments demonstrate that ReMoE consistently outperforms vanilla TopK-routed MoE across various model sizes, expert counts, and levels of granularity. Furthermore, ReMoE exhibits superior scalability with respect to the number of experts, surpassing traditional MoE architectures. The implementation based on Megatron-LM is available at https://github.com/thu-ml/ReMoE.
MoE의 라우터를 Top-K 대신 ReLU로 교체. 물론 ReLU는 활성화되는 Expert의 수를 통제할 수 없으니 L1 regularization을 사용해 Sparsity를 유도합니다. 아이러니하게도 Sparse Autoencoder에서 L1 regularization에서 Top-K로 나아간 것의 반대 방향이네요. (https://arxiv.org/abs/2406.04093)
The router of MoE is replaced with ReLU instead of Top-K. Since ReLU cannot control the number of activated experts, they induce sparsity using L1 regularization. Ironically, this is the reverse direction of sparse autoencoders, which progressed from L1 regularization to Top-K. (https://arxiv.org/abs/2406.04093)
#moe
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
(Weijia Shi, Xiaochuang Han, Chunting Zhou, Weixin Liang, Xi Victoria Lin, Luke Zettlemoyer, Lili Yu)

We present LlamaFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LlamaFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LlamaFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LlamaFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
Transfusion을 (https://arxiv.org/abs/2408.11039) Llama 3 체크포인트를 재활용해 학습한 모델. 다만 이미지와 텍스트 모달리티에 대해 서로 다른 Attention/FFN Weight를 사용했네요.
This model trained LlamaFusion (https://arxiv.org/abs/2408.11039) by recycling Llama 3 checkpoints. Notably, they used separate Attention/FFN weights for image and text modalities.
#image-generation #diffusion
Parallelized Autoregressive Visual Generation
(Yuqing Wang, Shuhuai Ren, Zhijie Lin, Yujin Han, Haoyuan Guo, Zhenheng Yang, Difan Zou, Jiashi Feng, Xihui Liu)

Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process. In this paper, we propose a simple yet effective approach for parallelized autoregressive visual generation that improves generation efficiency while preserving the advantages of autoregressive modeling. Our key insight is that parallel generation depends on visual token dependencies-tokens with weak dependencies can be generated in parallel, while strongly dependent adjacent tokens are difficult to generate together, as their independent sampling may lead to inconsistencies. Based on this observation, we develop a parallel generation strategy that generates distant tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent local tokens. Our approach can be seamlessly integrated into standard autoregressive models without modifying the architecture or tokenizer. Experiments on ImageNet and UCF-101 demonstrate that our method achieves a 3.6x speedup with comparable quality and up to 9.5x speedup with minimal quality degradation across both image and video generation tasks. We hope this work will inspire future research in efficient visual generation and unified autoregressive modeling. Project page: https://epiphqny.github.io/PAR-project.
Autoregressive 이미지 생성의 병렬화 방법. 멀리 떨어진 토큰들은 상관 관계가 낮기 때문에 병렬로 생성 가능하다는 아이디어입니다. Locality를 활용한 병렬화를 얼마 전 연구에서도 시도했죠. (https://arxiv.org/abs/2412.04062) Permuted Autoregressive 모델에서 시도한 병렬 생성도 그렇고 (https://arxiv.org/abs/2412.01827) 추론 효율화는 어떻게든 결과가 나오는군요.
A method for parallelizing autoregressive image generation. The idea is that distant tokens can be generated in parallel due to their low correlation. Parallelization using locality was also attempted in a recent study (https://arxiv.org/abs/2412.04062). Considering the parallel generation tried in permuted autoregressive models (https://arxiv.org/abs/2412.01827), it seems that it is always possible to improve inference efficiency.
#autoregressive-model #efficiency
Scaling 4D Representations
(João Carreira, Dilara Gokay, Michael King, Chuhan Zhang, Ignacio Rocco, Aravindh Mahendran, Thomas Albert Keck, Joseph Heyward, Skanda Koppula, Etienne Pot, Goker Erdogan, Yana Hasson, Yi Yang, Klaus Greff, Guillaume Le Moing, Sjoerd van Steenkiste, Daniel Zoran, Drew A. Hudson, Pedro Vélez, Luisa Polanía, Luke Friedman, Chris Duvarney, Ross Goroshin, Kelsey Allen, Jacob Walker, Rishabh Kabra, Eric Aboussouan, Jennifer Sun, Thomas Kipf, Carl Doersch, Viorica Pătrăucean, Dima Damen, Pauline Luc, Mehdi S. M. Sajjadi, Andrew Zisserman)

Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks – action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model – 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
3D + 시간에 대한 파운데이션 모델인데 기본적으로는 비디오 데이터에 대한 MAE군요.
여담이지만 TPUv6로 학습했는데 그래도 꽤 최근에 한 연구라는 의미일 수 있겠네요.
This is a foundation model for 3D space and time, which is essentially MAE applied to video data.
As a side note, they used TPUv6 for training, which might suggest that this research was conducted quite recently.
#self-supervision #video