



2024년 11월 6일

Inference Optimal VLMs Need Only One Visual Token but Larger Models
(Kevin Y. Li, Sachin Goyal, Joao D. Semedo, J. Zico Kolter)
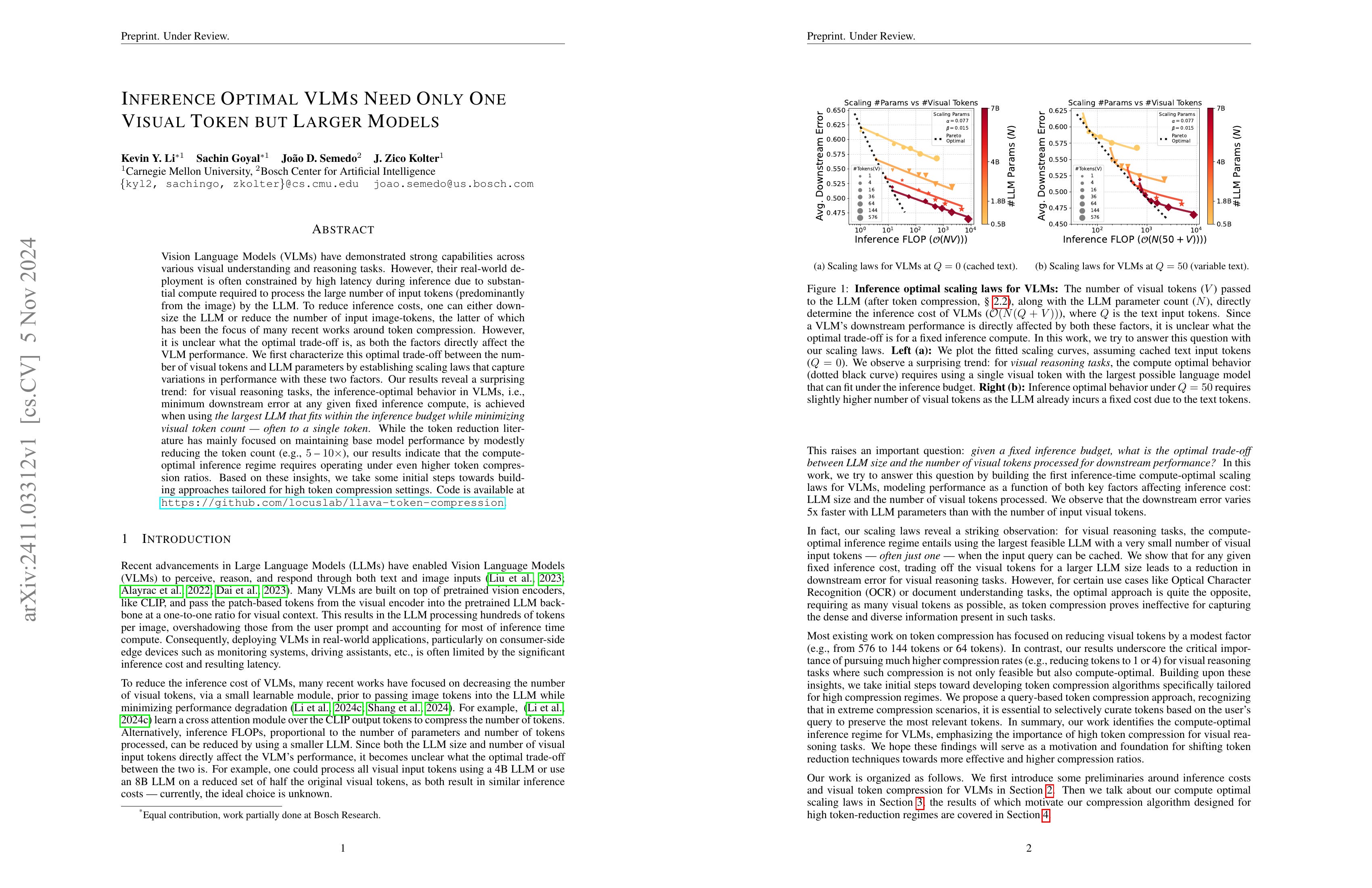
Vision Language Models (VLMs) have demonstrated strong capabilities across various visual understanding and reasoning tasks. However, their real-world deployment is often constrained by high latency during inference due to substantial compute required to process the large number of input tokens (predominantly from the image) by the LLM. To reduce inference costs, one can either downsize the LLM or reduce the number of input image-tokens, the latter of which has been the focus of many recent works around token compression. However, it is unclear what the optimal trade-off is, as both the factors directly affect the VLM performance. We first characterize this optimal trade-off between the number of visual tokens and LLM parameters by establishing scaling laws that capture variations in performance with these two factors. Our results reveal a surprising trend: for visual reasoning tasks, the inference-optimal behavior in VLMs, i.e., minimum downstream error at any given fixed inference compute, is achieved when using the largest LLM that fits within the inference budget while minimizing visual token count - often to a single token. While the token reduction literature has mainly focused on maintaining base model performance by modestly reducing the token count (e.g., 5−10×5−10×), our results indicate that the compute-optimal inference regime requires operating under even higher token compression ratios. Based on these insights, we take some initial steps towards building approaches tailored for high token compression settings. Code is available at https://github.com/locuslab/llava-token-compression.
이미지 토큰 수와 모델 크기의 트레이드오프 사이에서의 최적점을 Scaling Law로 탐색. 놀랍게도 토큰 수는 크게 줄이고 (1!) 모델을 키우는 것이 최적이었다고 하네요. 그렇지만 OCR에서는 모델 크기보다는 토큰 수가 성능을 결정했다고 합니다. 이미지 문제에서 언제나 엣지 케이스를 담당하고 있는 것이 OCR이죠.
Exploring the optimal trade-off between the number of image tokens and model size using scaling laws. Surprisingly, they found that drastically reducing the number of tokens (to just 1!) while increasing the model size was optimal. However, for OCR tasks, the number of tokens tended to determine performance more than model size. As always, OCR proves to be the edge case in image-related tasks.
#vision-language #ocr #scaling-law
Classification Done Right for Vision-Language Pre-Training
(Huang Zilong, Ye Qinghao, Kang Bingyi, Feng Jiashi, Fan Haoqi)

We introduce SuperClass, a super simple classification method for vision-language pre-training on image-text data. Unlike its contrastive counterpart CLIP who contrast with a text encoder, SuperClass directly utilizes tokenized raw text as supervised classification labels, without the need for additional text filtering or selection. Due to the absence of the text encoding as contrastive target, SuperClass does not require a text encoder and does not need to maintain a large batch size as CLIP does. SuperClass demonstrated superior performance on various downstream tasks, including classic computer vision benchmarks and vision language downstream tasks. We further explored the scaling behavior of SuperClass on model size, training length, or data size, and reported encouraging results and comparisons to CLIP. https://github.com/x-cls/superclass
이미지 백본 프리트레이닝을 캡션의 단어들에 대한 Bag of Words 예측으로 진행하는 방법. 순서에 대한 고려를 빼고 Bag of Words로 Objective를 바꾸는 것은 종종 등장하긴 하죠.
Pretrain image backbones by predicting a bag of words from the image captions. It is a frequently used approach to simplifying the objective by disregarding word order and using bag of words prediction.
#clip