



2024년 11월 4일 (1)

Learning to Achieve Goals with Belief State Transformers
(Edward S. Hu, Kwangjun Ahn, Qinghua Liu, Haoran Xu, Manan Tomar, Ada Langford, Dinesh Jayaraman, Alex Lamb, John Langford)

We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
Prefix와 Suffix의 조합에 대해 다음 토큰과 이전 토큰을 예측하는 Objective. FIM과 비슷하게 생각할 수 있지만 하나의 시퀀스에서 더 많은 학습 시그널을 추출한다고 생각할 수 있겠네요.
This approach uses an objective that predicts both the next token for prefixes and the previous token for suffixes in combinations of prefixes and suffixes. While it may be considered similar to FIM, it can be thought of as extracting more training signals from a single sequence.
#transformer
On Memorization of Large Language Models in Logical Reasoning
(Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, Ravi Kumar)

Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.
암기 vs 추론. 추론 과제로 파인튜닝을 했을 때 Perturbation을 통해 모델이 문제를 암기 혹은 추론 중 둘 중 어느 쪽으로 해결하는지를 체크하면 암기를 통해 문제를 푸는 경향이 나타나지만 동시에 추론 능력을 통한 일반화 또한 나타난다는 연구. 난이도가 높아질수록 암기 경향이 강해지는 것도 직관적이군요.
Memorization vs. reasoning. This study examines how models solve problems after fine-tuning on reasoning tasks, using perturbation to check whether they rely on memorization or reasoning. The results show that while models tend to memorize, they also demonstrate improved generalization through reasoning abilities. Interestingly, the tendency to rely on memorization increases as the difficulty of the problems increases, which is intuitive.
#reasoning
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
(Haiyang Wang, Yue Fan, Muhammad Ferjad Naeem, Yongqin Xian, Jan Eric Lenssen, Liwei Wang, Federico Tombari, Bernt Schiele)

Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a significant concern. This problem arises primarily from their dependence on a fixed number of parameters within linear projections. When architectural modifications (e.g., channel dimensions) are introduced, the entire model typically requires retraining from scratch. As model sizes continue growing, this strategy results in increasingly high computational costs and becomes unsustainable. To overcome this problem, we introduce TokenFormer, a natively scalable architecture that leverages the attention mechanism not only for computations among input tokens but also for interactions between tokens and model parameters, thereby enhancing architectural flexibility. By treating model parameters as tokens, we replace all the linear projections in Transformers with our token-parameter attention layer, where input tokens act as queries and model parameters as keys and values. This reformulation allows for progressive and efficient scaling without necessitating retraining from scratch. Our model scales from 124M to 1.4B parameters by incrementally adding new key-value parameter pairs, achieving performance comparable to Transformers trained from scratch while greatly reducing training costs. Code and models are available at https://github.com/Haiyang-W/TokenFormer.
트랜스포머의 Linear 레이어들을 학습 가능한 Key/Value 행렬과 토큰 사이의 Attention으로 대체. 과거 Learnable Key/Value로 Feed Forward를 대체할 수 있다는 연구가 생각나네요. (https://arxiv.org/abs/1907.01470) 이런 선택의 장점은 Key/Value 행렬의 토큰 크기를 늘리는 것으로 모델의 규모를 쉽게 확장시킬 수 있다는 것이죠. 재미있네요.
The linear layers of the transformer are replaced with attention between tokens and learnable key/value matrices. This reminds me of a previous study that showed feed forward layers could be replaced with learnable key/value matrices (https://arxiv.org/abs/1907.01470). The advantage of this approach is that it allows for easy scaling of the model simply by increasing the number of tokens in the key/value matrices. Interesting concept.
#transformer
Analyzing & Reducing the Need for Learning Rate Warmup in GPT Training
(Atli Kosson, Bettina Messmer, Martin Jaggi)

Learning Rate Warmup is a popular heuristic for training neural networks, especially at larger batch sizes, despite limited understanding of its benefits. Warmup decreases the update size Δw_t = η_t u_t early in training by using lower values for the learning rate η_t. In this work we argue that warmup benefits training by keeping the overall size of Δw_t limited, counteracting large initial values of u_t. Focusing on small-scale GPT training with AdamW/Lion, we explore the following question: Why and by which criteria are early updates u_t too large? We analyze different metrics for the update size including the ℓ_2-norm, resulting directional change, and impact on the representations of the network, providing a new perspective on warmup. In particular, we find that warmup helps counteract large angular updates as well as a limited critical batch size early in training. Finally, we show that the need for warmup can be significantly reduced or eliminated by modifying the optimizer to explicitly normalize u_t based on the aforementioned metrics.
LR Warmup이 필요한 이유는 무엇인가? 업데이트의 l2 Norm, 업데이트로 인한 파라미터의 각도 변화 및 Activation의 변화 측면에서 분석. Warmup이 이러한 변화가 지나치게 커지지 않도록 통제하는 측면에서 작동한다는 주장.
Why we need LR warmup? This paper analyzes the necessity from the perspectives of the L2 norm of updates, the angular change in parameters due to updates, and changes in activations. It argues that warmup controls these changes to prevent them from becoming excessively large.
#optimizer
Language Models can Self-Lengthen to Generate Long Texts
(Shanghaoran Quan, Tianyi Tang, Bowen Yu, An Yang, Dayiheng Liu, Bofei Gao, Jianhong Tu, Yichang Zhang, Jingren Zhou, Junyang Lin)

Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.
긴 길이의 텍스트를 생성할 수 있도록 학습. Generator와 Extender를 두고 학습시키는데 생성한 텍스트를 잘라서 연장하고 그 결과를 기반으로 다시 생성하는 식으로 주어진 텍스트를 연장하도록 Extender를 학습시키는 것이 핵심이군요.
The paper focuses on training language models to generate long texts. It employs a system with a Generator and an Extender. The key aspect is training the Extender to lengthen the text: it splits the text generated by the Generator, extends it, and then uses this extended result as a basis for further generation.
#alignment #long-context
SelfCodeAlign: Self-Alignment for Code Generation
(Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang)

Instruction tuning is a supervised fine-tuning approach that significantly improves the ability of large language models (LLMs) to follow human instructions. We propose SelfCodeAlign, the first fully transparent and permissive pipeline for self-aligning code LLMs without extensive human annotations or distillation. SelfCodeAlign employs the same base model for inference throughout the data generation process. It first extracts diverse coding concepts from high-quality seed snippets to generate new tasks. It then samples multiple responses per task, pairs each with test cases, and validates them in a sandbox environment. Finally, passing examples are selected for instruction tuning. In our primary experiments, we use SelfCodeAlign with CodeQwen1.5-7B to generate a dataset of 74k instruction-response pairs. Finetuning on this dataset leads to a model that achieves a 67.1 pass@1 on HumanEval+, surpassing CodeLlama-70B-Instruct despite being ten times smaller. Across all benchmarks, this finetuned model consistently outperforms the original version trained with OctoPack, the previous state-of-the-art method for instruction tuning without human annotations or distillation. Additionally, we show that SelfCodeAlign is effective across LLMs of various sizes, from 3B to 33B, and that the base models can benefit more from alignment with their own data distribution. We further validate each component's effectiveness in our pipeline, showing that SelfCodeAlign outperforms both direct distillation from GPT-4o and leading GPT-3.5-based distillation methods, such as OSS-Instruct and Evol-Instruct. SelfCodeAlign has also led to the creation of StarCoder2-Instruct, the first fully transparent, permissively licensed, and self-aligned code LLM that achieves state-of-the-art coding performance.
코드 Instruction에 대한 정렬 방법. 코드 스니펫 추출, Instruction 생성, 테스트 생성 및 검증이라는 순서인데 가장 흥미로운 점은 Instruction 튜닝을 거친 모델이 아닌 베이스 모델로 데이터 생성 과정을 진행했다는 것이네요.
This paper presents an alignment method for code instructions. The process involves code snippet extraction, instruction generation, and test case generation and validation. The most interesting point is that the entire data generation process is carried out using the base model, not a model that has undergone instruction tuning.
#instruction-tuning #synthetic-data
Weight decay induces low-rank attention layers
(Seijin Kobayashi, Yassir Akram, Johannes Von Oswald)

The effect of regularizers such as weight decay when training deep neural networks is not well understood. We study the influence of weight decay as well as L2-regularization when training neural network models in which parameter matrices interact multiplicatively. This combination is of particular interest as this parametrization is common in attention layers, the workhorse of transformers. Here, key-query, as well as value-projection parameter matrices, are multiplied directly with each other: W_K^TW_Q and PW_V. We extend previous results and show on one hand that any local minimum of a L2-regularized loss of the form L(AB^⊤) + λ(∥A∥^2 + ∥B∥^2) coincides with a minimum of the nuclear norm-regularized loss L(AB^⊤) + λ∥AB^⊤∥_*, and on the other hand that the 2 losses become identical exponentially quickly during training. We thus complement existing works linking L2-regularization with low-rank regularization, and in particular, explain why such regularization on the matrix product affects early stages of training. Based on these theoretical insights, we verify empirically that the key-query and value-projection matrix products W_K^TW_Q, PW_V within attention layers, when optimized with weight decay, as usually done in vision tasks and language modelling, indeed induce a significant reduction in the rank of W_K^TW_Q and PW_V, even in fully online training. We find that, in accordance with existing work, inducing low rank in attention matrix products can damage language model performance, and observe advantages when decoupling weight decay in attention layers from the rest of the parameters.
Attention 레이어의 Linear Weight에 대한 Weight Decay가 Attention Logit 등에 대해 Low Rank Regularization을 부과할 수 있다는 주장. 따라서 Attention에 대해서는 다른 FFN보다 낮은 Weight Decay를 사용할 필요가 있을 수 있다는 아이디어네요.
This paper argues that applying weight decay to the linear weights in attention layers can induce low-rank regularization on attention logits and other components. Consequently, it suggests that attention layers may require lower weight decay compared to FFNs.
#transformer #regularization
What Happened in LLMs Layers when Trained for Fast vs. Slow Thinking: A Gradient Perspective
(Ming Li, Yanhong Li, Tianyi Zhou)
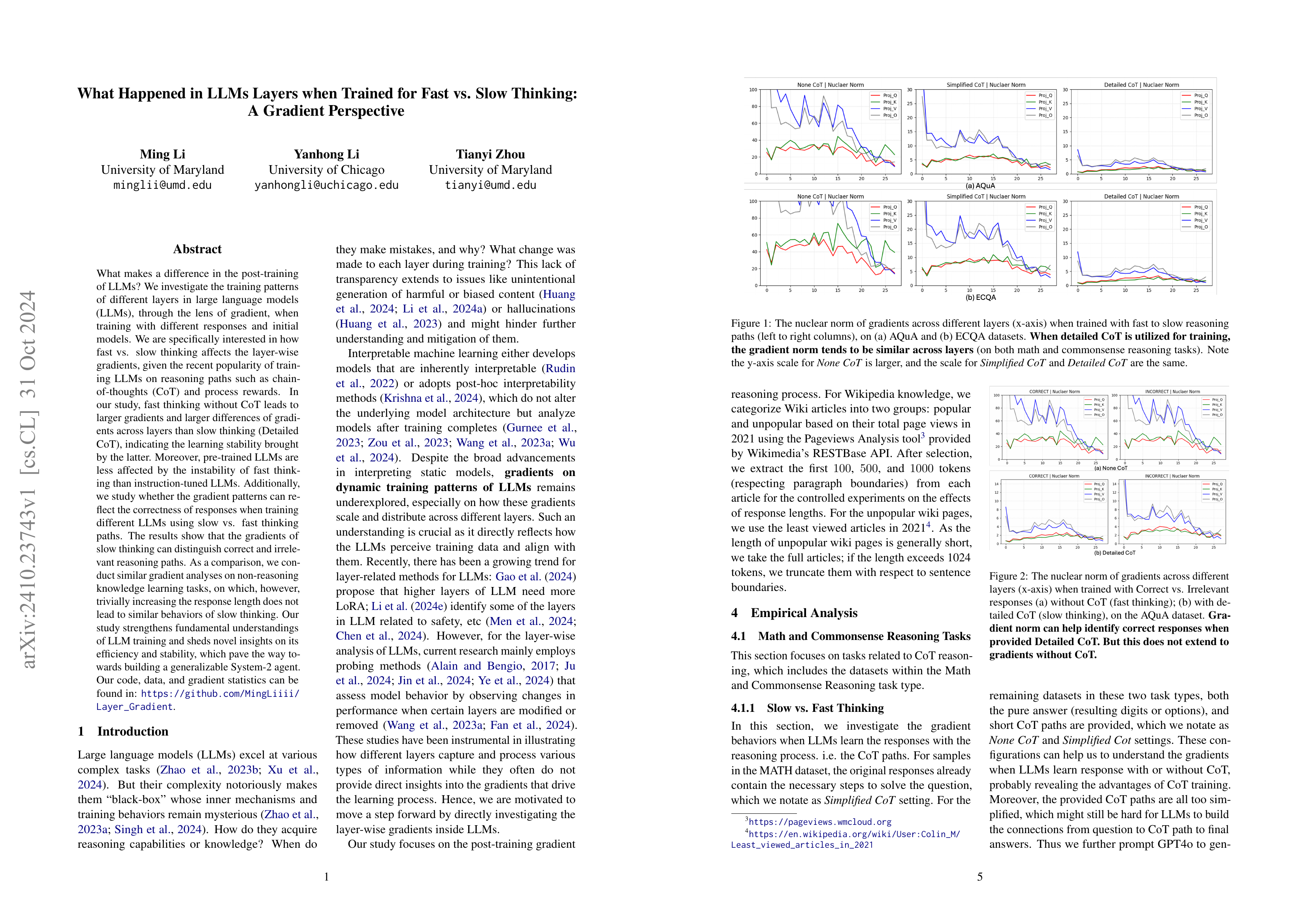
What makes a difference in the post-training of LLMs? We investigate the training patterns of different layers in large language models (LLMs), through the lens of gradient, when training with different responses and initial models. We are specifically interested in how fast vs. slow thinking affects the layer-wise gradients, given the recent popularity of training LLMs on reasoning paths such as chain-of-thoughts (CoT) and process rewards. In our study, fast thinking without CoT leads to larger gradients and larger differences of gradients across layers than slow thinking (Detailed CoT), indicating the learning stability brought by the latter. Moreover, pre-trained LLMs are less affected by the instability of fast thinking than instruction-tuned LLMs. Additionally, we study whether the gradient patterns can reflect the correctness of responses when training different LLMs using slow vs. fast thinking paths. The results show that the gradients of slow thinking can distinguish correct and irrelevant reasoning paths. As a comparison, we conduct similar gradient analyses on non-reasoning knowledge learning tasks, on which, however, trivially increasing the response length does not lead to similar behaviors of slow thinking. Our study strengthens fundamental understandings of LLM training and sheds novel insights on its efficiency and stability, which pave the way towards building a generalizable System-2 agent. Our code, data, and gradient statistics can be found in: https://github.com/MingLiiii/Layer_Gradient.
자세한 Chain of Thought가 주어진 경우, 그리고 정답이 주어진 경우가 오답이 주어진 경우보다 레이어 사이의 그래디언트 Nuclear Norm의 차이가 줄어든다는 결과. 지식과 관련된 경우에는 입력의 길이나 오답 여부에 따른 차이가 잘 나타나지 않았다고 하네요. 직관적이면서도 흥미롭군요.
The results show that when detailed chain of thought is provided, and when correct answers are given instead of incorrect ones, the difference in the nuclear norm of gradients between layers decreases. Interestingly, for knowledge-related problems, differences due to input length or correctness were not as apparent. These findings are both intuitive and intriguing.
#reasoning
What is Wrong with Perplexity for Long-context Language Modeling?
(Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, Yisen Wang)

Handling long-context inputs is crucial for large language models (LLMs) in tasks such as extended conversations, document summarization, and many-shot in-context learning. While recent approaches have extended the context windows of LLMs and employed perplexity (PPL) as a standard evaluation metric, PPL has proven unreliable for assessing long-context capabilities. The underlying cause of this limitation has remained unclear. In this work, we provide a comprehensive explanation for this issue. We find that PPL overlooks key tokens, which are essential for long-context understanding, by averaging across all tokens and thereby obscuring the true performance of models in long-context scenarios. To address this, we propose \textbf{LongPPL}, a novel metric that focuses on key tokens by employing a long-short context contrastive method to identify them. Our experiments demonstrate that LongPPL strongly correlates with performance on various long-context benchmarks (e.g., Pearson correlation of -0.96), significantly outperforming traditional PPL in predictive accuracy. Additionally, we introduce \textbf{LongCE} (Long-context Cross-Entropy) loss, a re-weighting strategy for fine-tuning that prioritizes key tokens, leading to consistent improvements across diverse benchmarks. In summary, these contributions offer deeper insights into the limitations of PPL and present effective solutions for accurately evaluating and enhancing the long-context capabilities of LLMs. Code is available at https://github.com/PKU-ML/LongPPL.
Perplexity를 Long Context에 대한 평가 지표로 사용할 수 있도록 개선. Long Context가 주어졌을 때의 각 토큰의 Loss와 Short Context 하에서의 Loss의 차이를 통해 예측에 실제로 Long Context 정보가 필요한 토큰을 걸러내는 방법. Long Context 벤치마크와 높은 상관관계를 달성했군요. 반대로 이렇게 토큰을 걸러내서 학습하는 Long Context 튜닝 방법도 생각할 수 있습니다. 다만 Loss를 계산할 모델이 따로 필요하다는 것이 문제이긴 합니다.
An improvement to perplexity as an evaluation metric for long contexts. The method filters tokens that actually require long-context information by comparing the loss difference between long and short contexts. It achieves high correlation with long-context benchmarks. Conversely, we can also consider a long-context tuning method that focuses on training these filtered tokens. However, a limitation is that it requires a separate model to calculate the loss.
#long-context
Scaling LLM Inference with Optimized Sample Compute Allocation
(Kexun Zhang, Shang Zhou, Danqing Wang, William Yang Wang, Lei Li)
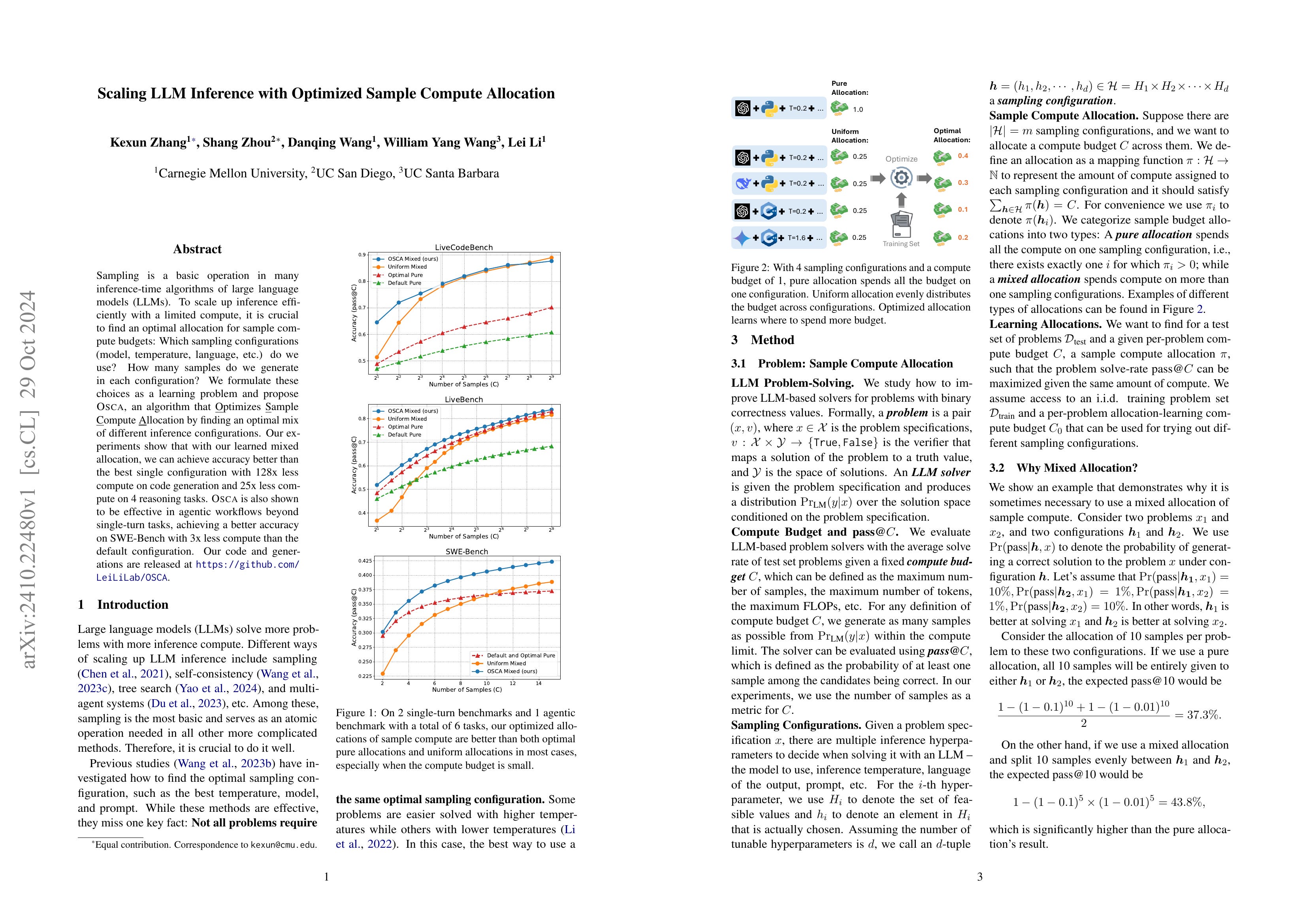
Sampling is a basic operation in many inference-time algorithms of large language models (LLMs). To scale up inference efficiently with a limited compute, it is crucial to find an optimal allocation for sample compute budgets: Which sampling configurations (model, temperature, language, etc.) do we use? How many samples do we generate in each configuration? We formulate these choices as a learning problem and propose OSCA, an algorithm that Optimizes Sample Compute Allocation by finding an optimal mix of different inference configurations. Our experiments show that with our learned mixed allocation, we can achieve accuracy better than the best single configuration with 128x less compute on code generation and 25x less compute on 4 reasoning tasks. OSCA is also shown to be effective in agentic workflows beyond single-turn tasks, achieving a better accuracy on SWE-Bench with 3x less compute than the default configuration. Our code and generations are released at https://github.com/LeiLiLab/OSCA.
테스트 시점 탐색을 위한 다양한 Temperature 등의 세팅을 결정하는 방법.
A method for determining various settings, such as temperature, for test-time search.
#search