



2024년 10월 7일

A Spark of Vision-Language Intelligence: 2-Dimensional Autoregressive Transformer for Efficient Finegrained Image Generation
(Liang Chen, Sinan Tan, Zefan Cai, Weichu Xie, Haozhe Zhao, Yichi Zhang, Junyang Lin, Jinze Bai, Tianyu Liu, Baobao Chang)

This work tackles the information loss bottleneck of vector-quantization (VQ) autoregressive image generation by introducing a novel model architecture called the 2-Dimensional Autoregression (DnD) Transformer. The DnD-Transformer predicts more codes for an image by introducing a new autoregression direction, \textit{model depth}, along with the sequence length direction. Compared to traditional 1D autoregression and previous work utilizing similar 2D image decomposition such as RQ-Transformer, the DnD-Transformer is an end-to-end model that can generate higher quality images with the same backbone model size and sequence length, opening a new optimization perspective for autoregressive image generation. Furthermore, our experiments reveal that the DnD-Transformer's potential extends beyond generating natural images. It can even generate images with rich text and graphical elements in a self-supervised manner, demonstrating an understanding of these combined modalities. This has not been previously demonstrated for popular vision generative models such as diffusion models, showing a spark of vision-language intelligence when trained solely on images. Code, datasets and models are open at https://github.com/chenllliang/DnD-Transformer.
요새 RQ-VAE로 (https://arxiv.org/abs/2203.01941) VQ의 제약을 해소하려는 연구들이 많이 나오는군요. 16x 다운샘플링, 16K Vocab, 8개의 코드를 사용하니 텍스트 이미지에 대해서도 거의 완벽하게 Reconstruction이 되는군요. OCR을 고려했다는 것이 마음에 드네요.
8개 코드를 생성하는 것이 문제인데 되도록 한 스텝 내에서 해결이 가능하도록 레이 어를 나눠 하나씩 생성해나가도록 설정했습니다. 이쪽도 꽤 흥미로운 디자인이네요.
Recently, there have been many studies trying to overcome the limitations of VQ using RQ-VAE (https://arxiv.org/abs/2203.01941). With 16x downsampling, a 16K vocabulary, and 8 codes, it's possible to achieve almost perfect reconstruction even for images containing text. I appreciate that they considered OCR in their approach.
The main challenge is generating 8 codes efficiently. In this work, the authors designed the model to generate one code per block of layers, allowing it to produce all codes within a single step. I find this design quite interesting.
#vq #autoregressive-model #image-generation
Movie Gen: A Cast of Media Foundation Models
(The Movie Gen team @ Meta)

We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user’s image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
30B 16초, 16 fps Text-to-Image/Video 모델과 13B Video/Text-to-Audio 모델. VAE는 8x8x8 패치군요. 생성 백본에서는 2x Spatial Downsampling을 추가적으로 합니다. 텍스트 인코더로는 UL2, ByT5, MetaCLIP의 조합이고 7B Spatial Upsampler 사용. 그래서 대략 73K 토큰 입력이 되는군요.
H100 6000대 정도가 있다면 이런 모델을 학습시켜보는 것도 재미있을 것 같네요. 물론 데이터를 준비하는 것이 참 지난한 과정이었을 것 같긴 합니다만.
30B 16 second, 16 fps text-to-image/video model, and 13B video/text-to-audio model. They have used 8x8x8 patch VAE. Also, the generative backbones includes an additional 2x spatial downsampling. For text encoders, they use a combination of UL2, ByT5, and MetaCLIP. And 7B spatial upsampler is applied. This results in approximately 73K tokens for input.
It would be interesting to train such models if you had about 6000 H100 GPUs. Of course, preparing the data for this would likely have been a very arduous process.
#video-generation #flow-matching
Revisit Large-Scale Image-Caption Data in Pre-training Multimodal Foundation Models
(Zhengfeng Lai, Vasileios Saveris, Chen Chen, Hong-You Chen, Haotian Zhang, Bowen Zhang, Juan Lao Tebar, Wenze Hu, Zhe Gan, Peter Grasch, Meng Cao, Yinfei Yang)

Recent advancements in multimodal models highlight the value of rewritten captions for improving performance, yet key challenges remain. For example, while synthetic captions often provide superior quality and image-text alignment, it is not clear whether they can fully replace AltTexts: the role of synthetic captions and their interaction with original web-crawled AltTexts in pre-training is still not well understood. Moreover, different multimodal foundation models may have unique preferences for specific caption formats, but efforts to identify the optimal captions for each model remain limited. In this work, we propose a novel, controllable, and scalable captioning pipeline designed to generate diverse caption formats tailored to various multimodal models. By examining Short Synthetic Captions (SSC) towards Dense Synthetic Captions (DSC+) as case studies, we systematically explore their effects and interactions with AltTexts across models such as CLIP, multimodal LLMs, and diffusion models. Our findings reveal that a hybrid approach that keeps both synthetic captions and AltTexts can outperform the use of synthetic captions alone, improving both alignment and performance, with each model demonstrating preferences for particular caption formats. This comprehensive analysis provides valuable insights into optimizing captioning strategies, thereby advancing the pre-training of multimodal foundation models.
이미지-텍스트 페어에서 합성 데이터의 사용, 특히 여러 합성 데이터의 스타일(상세한 정도, Alt Text를 결합하는 여부 등), 그리고 CLIP/Multimodal LLM/Text-to-Image 모델에 대한 비교 분석. 상세한 캡션이 좋고 Alt Text를 결합하는 것이 종종 좋을 수 있다는 느낌이네요.
This paper presents a comparative analysis of using synthetic data for image-text pairs, focusing on various styles of synthetic captions (including level of detail and whether to incorporate alt text), and their effects on CLIP, multimodal LLM, and text-to-image models. The overall findings suggest that detailed captions are generally more effective, and incorporating alt text often proves beneficial.
#synthetic-data #image-text #captioning
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
(Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Taco Cohen, Gabriel Synnaeve)

Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
Execution Feedback을 사용해 모델을 학습시키는 방법인데 여기의 핵심은 추론 시점에서 Execution Feedback을 사용해 결과를 개선할 수 있도록 학습시키는 것에 있네요. 공개/비공개 테스트를 나눈 다음 공개 테스트의 결과를 입력으로 사용해 개선하도록 루프를 돌고, 완료 시점에서 비공개 테스트의 결과를 합쳐 PPO를 하는 방식입니다.
This method uses execution feedback to train the model. The key aspect is that it trains models to improve results using execution feedback at inference time. The process involves splitting the test set into public and private. It then runs a loop where it uses the results from the public tests as input to improve the model's output. At the end of this process, it combines the results from the private test sets and applies PPO.
#feedback #reasoning
Step-by-Step Reasoning for Math Problems via Twisted Sequential Monte Carlo
(Shengyu Feng, Xiang Kong, Shuang Ma, Aonan Zhang, Dong Yin, Chong Wang, Ruoming Pang, Yiming Yang)

Augmenting the multi-step reasoning abilities of Large Language Models (LLMs) has been a persistent challenge. Recently, verification has shown promise in improving solution consistency by evaluating generated outputs. However, current verification approaches suffer from sampling inefficiencies, requiring a large number of samples to achieve satisfactory performance. Additionally, training an effective verifier often depends on extensive process supervision, which is costly to acquire. In this paper, we address these limitations by introducing a novel verification method based on Twisted Sequential Monte Carlo (TSMC). TSMC sequentially refines its sampling effort to focus exploration on promising candidates, resulting in more efficient generation of high-quality solutions. We apply TSMC to LLMs by estimating the expected future rewards at partial solutions. This approach results in a more straightforward training target that eliminates the need for step-wise human annotations. We empirically demonstrate the advantages of our method across multiple math benchmarks, and also validate our theoretical analysis of both our approach and existing verification methods.
Majority Voting이나 Reward Model을 사용한 Verification을 Importance Sampling으로 해석한 다음 Importance Sampling의 샘플링 효율성을 높이기 위한 방법으로 Twisted Sequential Monte Carlo를 사용. (https://arxiv.org/abs/2404.17546) 유도를 쭉 따라가면 결과적으로 Value Function을 추정해서 활용하는 형태가 되는군요.
The paper interprets majority voting or verification using a reward model as a form of importance sampling. To improve the sampling efficiency of importance sampling, they employ Twisted Sequential Monte Carlo (https://arxiv.org/abs/2404.17546). Following the derivation, the resulting algorithm essentially utilizes a value function for sampling.
#search
General Preference Modeling with Preference Representations for Aligning Language Models
(Yifan Zhang, Ge Zhang, Yue Wu, Kangping Xu, Quanquan Gu)

Modeling human preferences is crucial for aligning foundation models with human values. Traditional reward modeling methods, such as the Bradley-Terry (BT) reward model, fall short in expressiveness, particularly in addressing intransitive preferences. Although supervised pair preference models (PairPM) can express general preferences, their implementation is highly ad-hoc and cannot guarantee a consistent preference probability of compared pairs. Additionally, they impose high computational costs due to their quadratic query complexity when comparing multiple responses. In this paper, we introduce preference representation learning, an approach that embeds responses into a latent space to capture intricate preference structures efficiently, achieving linear query complexity. Additionally, we propose preference score-based General Preference Optimization (GPO), which generalizes reward-based reinforcement learning from human feedback. Experimental results show that our General Preference representation model (GPM) outperforms the BT reward model on the RewardBench benchmark with a margin of up to 5.6% and effectively models cyclic preferences where any BT reward model behaves like a random guess. Furthermore, evaluations on downstream tasks such as AlpacaEval2.0 and MT-Bench, following the language model post-training with GPO and our general preference model, reveal substantial performance improvements with margins up to 9.3%. These findings indicate that our method may enhance the alignment of foundation models with nuanced human values. The code is available at https://github.com/general-preference/general-preference-model.
여러 응답에 대해서 선호의 Intransitivity를 모델링하기 위한 방법. 각 응답에 대한 임베딩 벡터를 추출한 다음 Skew-symmetric Operator를 사용해 스코어를 계산합니다.
A method for modeling the intransitivity of preferences among multiple responses. Embedding vectors are extracted for each response, then scores are calculated using a skew-symmetric operator.
#rlhf #reward-model
How to Train Long-Context Language Models (Effectively)
(Tianyu Gao, Alexander Wettig, Howard Yen, Danqi Chen)

We study continued training and supervised fine-tuning (SFT) of a language model (LM) to make effective use of long-context information. We first establish a reliable evaluation protocol to guide model development -- Instead of perplexity or simple needle-in-a-haystack (NIAH) tests, we use a broad set of long-context tasks, and we evaluate models after SFT with instruction data as this better reveals long-context abilities. Supported by our robust evaluations, we run thorough experiments to decide the data mix for continued pre-training, the instruction tuning dataset, and many other design choices. We find that (1) code repositories and books are excellent sources of long data, but it is crucial to combine them with high-quality short data; (2) training with a sequence length beyond the evaluation length boosts long-context performance; (3) for SFT, using only short instruction datasets yields strong performance on long-context tasks. Our final model, ProLong-8B, which is initialized from Llama-3 and trained on 40B tokens, demonstrates state-of-the-art long-context performance among similarly sized models at a length of 128K. ProLong outperforms Llama-3.18B-Instruct on the majority of long-context tasks despite having seen only 5% as many tokens during long-context training. Additionally, ProLong can effectively process up to 512K tokens, one of the longest context windows of publicly available LMs.
Long Context 튜닝 레시피. 짧은 데이터를 섞은 긴 텍스트들을 준비하고, 오래, 평가 시점보다 더 긴 길이에 대해 튜닝하는 것이 좋다는 결론.
Recipe for long context tuning: Prepare long texts mixed with short data, and train for an extended period using sequences longer than those used during evaluation.
#long-context
LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning
(Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, Wanli Ouyang, Dongzhan Zhou)

This paper presents an advanced mathematical problem-solving framework, LLaMA-Berry, for enhancing the mathematical reasoning ability of Large Language Models (LLMs). The framework combines Monte Carlo Tree Search (MCTS) with iterative Self-Refine to optimize the reasoning path and utilizes a pairwise reward model to evaluate different paths globally. By leveraging the self-critic and rewriting capabilities of LLMs, Self-Refine applied to MCTS (SR-MCTS) overcomes the inefficiencies and limitations of conventional step-wise and greedy search algorithms by fostering a more efficient exploration of solution spaces. Pairwise Preference Reward Model~(PPRM), inspired by Reinforcement Learning from Human Feedback (RLHF), is then used to model pairwise preferences between solutions, utilizing an Enhanced Borda Count (EBC) method to synthesize these preferences into a global ranking score to find better answers. This approach addresses the challenges of scoring variability and non-independent distributions in mathematical reasoning tasks. The framework has been tested on general and advanced benchmarks, showing superior performance in terms of search efficiency and problem-solving capability compared to existing methods like ToT and rStar, particularly in complex Olympiad-level benchmarks, including GPQA, AIME24 and AMC23.
MCTS + Self-Refine + Pairwise RM. Pairwise RM은 PRM800K와 OpenMathInstruct-1으로 학습되었습니다. 앞으로 Reasoning에 대한 연구들이 쏟아질 텐데 그 중에서 좋은 접근을 발견할 수 있는 취향이 중요해질 것 같네요.
MCTS + Self-Refine + Pairwise RM. The Pairwise RM was trained using PRM800K and OpenMathInstruct-1. We can expect a flood of research on reasoning in the near future, and developing a discerning taste for identifying promising approaches will become crucial.
#search #mcts
MA-RLHF: Reinforcement Learning from Human Feedback with Macro Actions
(Yekun Chai, Haoran Sun, Huang Fang, Shuohuan Wang, Yu Sun, Hua Wu)

Reinforcement learning from human feedback (RLHF) has demonstrated effectiveness in aligning large language models (LLMs) with human preferences. However, token-level RLHF suffers from the credit assignment problem over long sequences, where delayed rewards make it challenging for the model to discern which actions contributed to successful outcomes. This hinders learning efficiency and slows convergence. In this paper, we propose MA-RLHF, a simple yet effective RLHF framework that incorporates macro actions -- sequences of tokens or higher-level language constructs -- into the learning process. By operating at this higher level of abstraction, our approach reduces the temporal distance between actions and rewards, facilitating faster and more accurate credit assignment. This results in more stable policy gradient estimates and enhances learning efficiency within each episode, all without increasing computational complexity during training or inference. We validate our approach through extensive experiments across various model sizes and tasks, including text summarization, dialogue generation, question answering, and program synthesis. Our method achieves substantial performance improvements over standard RLHF, with performance gains of up to 30% in text summarization and code generation, 18% in dialogue, and 8% in question answering tasks. Notably, our approach reaches parity with vanilla RLHF 1.7x to 2x faster in terms of training time and continues to outperform it with further training. We will make our code and data publicly available at https://github.com/ernie-research/MA-RLHF .
토큰 단위가 아니라 토큰의 집합 단위로 PPO를 하자는 아이디어. 토큰 단위의 Credit Assignment가 어렵고 의미적으로 너무 작은 단위라는 발상이군요.
The idea is to perform PPO at the level of token groups rather than individual tokens. This approach stems from the idea that credit assignment at the token level is difficult and that tokens are too small a unit for capturing semantic meaning.
#rlhf
ReGenesis: LLMs can Grow into Reasoning Generalists via Self-Improvement
(Xiangyu Peng, Congying Xia, Xinyi Yang, Caiming Xiong, Chien-Sheng Wu, Chen Xing)

Post-training Large Language Models (LLMs) with explicit reasoning trajectories can enhance their reasoning abilities. However, acquiring such high-quality trajectory data typically demands meticulous supervision from humans or superior models, which can be either expensive or license-constrained. In this paper, we explore how far an LLM can improve its reasoning by self-synthesizing reasoning paths as training data without any additional supervision. Existing self-synthesizing methods, such as STaR, suffer from poor generalization to out-of-domain (OOD) reasoning tasks. We hypothesize it is due to that their self-synthesized reasoning paths are too task-specific, lacking general task-agnostic reasoning guidance. To address this, we propose Reasoning Generalist via Self-Improvement (ReGenesis), a method to self-synthesize reasoning paths as post-training data by progressing from abstract to concrete. More specifically, ReGenesis self-synthesizes reasoning paths by converting general reasoning guidelines into task-specific ones, generating reasoning structures, and subsequently transforming these structures into reasoning paths, without the need for human-designed task-specific examples used in existing methods. We show that ReGenesis achieves superior performance on all in-domain and OOD settings tested compared to existing methods. For six OOD tasks specifically, while previous methods exhibited an average performance decrease of approximately 4.6% after post training, ReGenesis delivers around 6.1% performance improvement. We also conduct in-depth analysis of our framework and show ReGenesis is effective across various LLMs and design choices.
추론에 대해 학습시키면 특정 과제에 특화된 추론 패턴을 학습해서 일반화가 어려워진다는 착상. 일반적인 추론 전략을 가져와서 구체적인 과제에 맞는 전략으로 수정하고, 이 전략에 따라 추론의 얼개를 작성한 다음 실제 추론을 생성하는 방법. 일반적인 추론 전략을 설정한다는 것은 Self-Discover와 (https://arxiv.org/abs/2402.03620) 비슷하네요.
The key insight is that training models for reasoning often leads to learning task-specific reasoning patterns, making generalization difficult. The proposed method involves taking general reasoning strategies, adapting them to specific tasks, then creating a framework for reasoning based on these strategies, and finally generating the actual reasoning steps. The approach of establishing general reasoning strategies is similar to that of Self-Discover (https://arxiv.org/abs/2402.03620).
#reasoning
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
(Jintao Zhang, Jia wei, Pengle Zhang, Jun Zhu, Jianfei Chen)

The transformer architecture predominates across various models. As the heart of the transformer, attention has a computational complexity of O(N^2), compared to O(N) for linear transformations. When handling large sequence lengths, attention becomes the primary time-consuming component. Although quantization has proven to be an effective method for accelerating model inference, existing quantization methods primarily focus on optimizing the linear layer. In response, we first analyze the feasibility of quantization in attention detailedly. Following that, we propose SageAttention, a highly efficient and accurate quantization method for attention. The OPS (operations per second) of our approach outperforms FlashAttention2 and xformers by about 2.1 times and 2.7 times, respectively. SageAttention also achieves superior accuracy performance over FlashAttention3. Comprehensive experiments confirm that our approach incurs almost no end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation.
8 Bit Flash Attention. Quantized Flash Attention의 구현은 이전에도 있었는데 (https://arxiv.org/abs/2409.16997) 이쪽은 어떻게 Quantization을 해야할 것인가에 대해서 탐색을 많이 했네요.
8-Bit Flash Attention. While implementations of Quantized Flash Attention have existed before (https://arxiv.org/abs/2409.16997), this study extensively explores how quantization should be applied.
#efficiency
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices
(Andres Potapczynski, Shikai Qiu, Marc Finzi, Christopher Ferri, Zixi Chen, Micah Goldblum, Bayan Bruss, Christopher De Sa, Andrew Gordon Wilson)
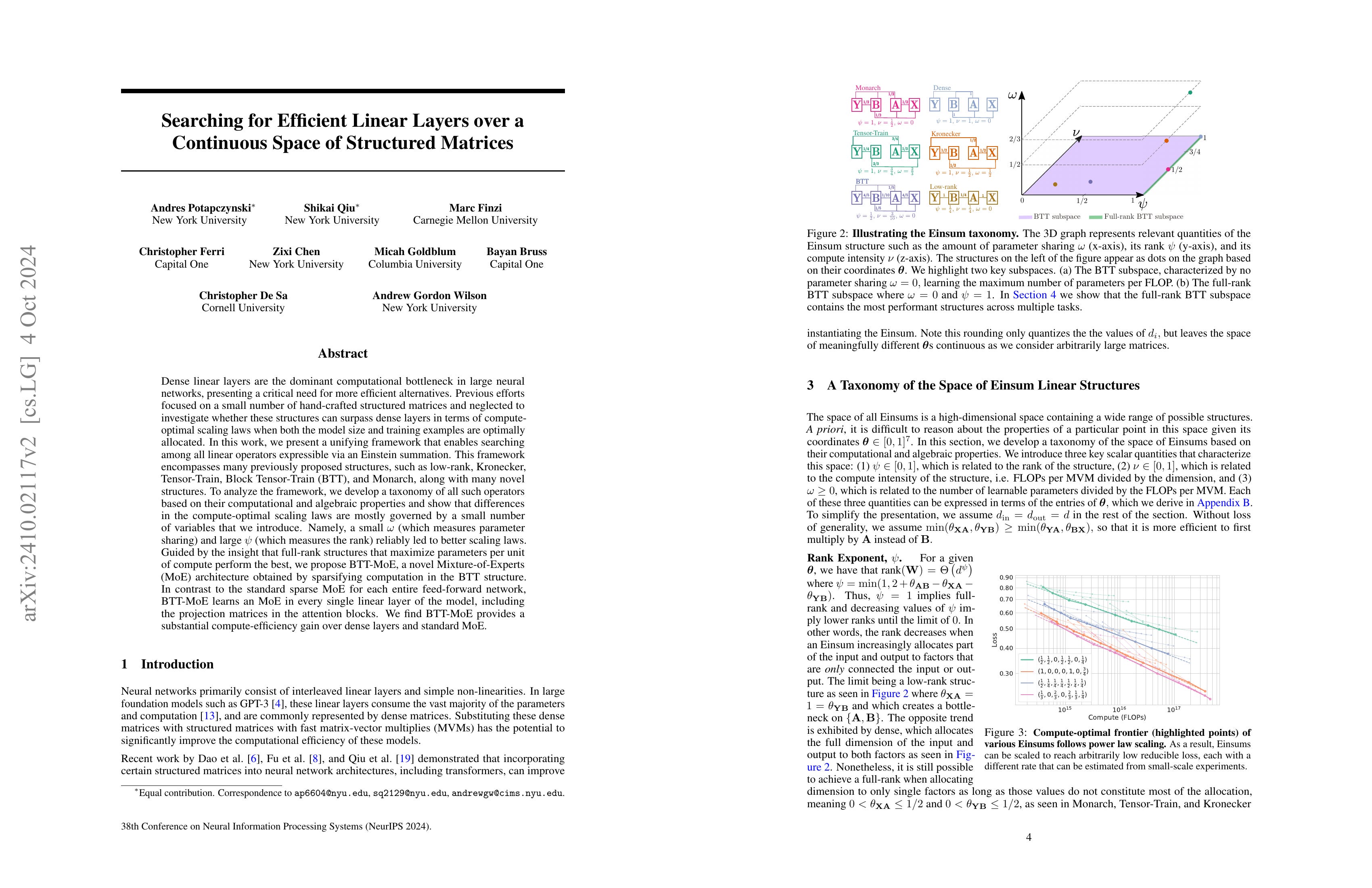
Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts focused on a small number of hand-crafted structured matrices and neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, Block Tensor-Train (BTT), and Monarch, along with many novel structures. To analyze the framework, we develop a taxonomy of all such operators based on their computational and algebraic properties and show that differences in the compute-optimal scaling laws are mostly governed by a small number of variables that we introduce. Namely, a small ω (which measures parameter sharing) and large ψ (which measures the rank) reliably led to better scaling laws. Guided by the insight that full-rank structures that maximize parameters per unit of compute perform the best, we propose BTT-MoE, a novel Mixture-of-Experts (MoE) architecture obtained by sparsifying computation in the BTT structure. In contrast to the standard sparse MoE for each entire feed-forward network, BTT-MoE learns an MoE in every single linear layer of the model, including the projection matrices in the attention blocks. We find BTT-MoE provides a substantial compute-efficiency gain over dense layers and standard MoE.
Tensor Train 같은 Structured Matrix를 사용하는 방법들을 einsum으로 통합한 다음 Scaling Law를 추정. 결과적으로는 Dense 세팅을 능가하는 경우는 없었습니다. MoE의 경우에는 Block Tensor Train이 조금 더 나은 결과가 나타났는데 이쪽은 Attention에도 MoE를 적용했기에 동등한 비교라기에는 좀 어려울 수 있겠네요. 이전의 연구에서도 (https://arxiv.org/abs/2406.06248) Structured Matrix로 더 나은 결과를 얻기는 어려웠던 것 같습니다.
The paper unifies methods using structured matrices like Tensor Train into an einsum framework and estimates their scaling laws. Ultimately, none of the methods outperformed the dense matrix setting. For MoE, Block Tensor Train showed slightly better results, but this comparison may not be entirely fair as they applied MoE to attention mechanisms as well. Previous research (https://arxiv.org/abs/2406.06248) also suggested that it's challenging to achieve better results using structured matrices.
#efficient-training #scaling-law
Selective Attention Improves Transformer
(Yaniv Leviathan, Matan Kalman, Yossi Matias)

Unneeded elements in the attention's context degrade performance. We introduce Selective Attention, a simple parameter-free change to the standard attention mechanism which reduces attention to unneeded elements. Selective attention improves language modeling performance in a variety of model sizes and context lengths. For example, a range of transformers trained with the language modeling objective on C4 with selective attention perform equivalently to standard transformers with ~2X more heads and parameters in their attention modules. Selective attention also allows decreasing the size of the attention's context buffer, leading to meaningful reductions in the memory and compute requirements during inference. For example, transformers with 100M parameters trained on C4 with context sizes of 512, 1,024, and 2,048 need 16X, 25X, and 47X less memory for their attention module, respectively, when equipped with selective attention, as those without selective attention, with the same validation perplexity.
Attention Logit에 대한 cumsum을 사용한 Positional Encoding. Contextual Position Encoding과 (https://arxiv.org/abs/2405.18719) 비슷한 느낌이 나네요.
효과가 나타나긴 하는데 가장 중요한 문제는 이를 효율적으로 계산할 수 있는 Attention 구현이 가능한가 하는 것이겠죠.
Positional encoding using cumsum on attention logits. This seems similar to Contextual Position Encoding (https://arxiv.org/abs/2405.18719).
The method does show performance improvements, but the important question is whether it's possible to implement an attention kernel that can calculate this efficiently.
#positional-encoding
Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
(Ulyana Piterbarg, Lerrel Pinto, Rob Fergus)

Software engineers mainly write code by editing existing programs. In contrast, large language models (LLMs) autoregressively synthesize programs in a single pass. One explanation for this is the scarcity of open-sourced edit data. While high-quality instruction data for code synthesis is already scarce, high-quality edit data is even scarcer. To fill this gap, we develop a synthetic data generation algorithm called LintSeq. This algorithm refactors existing code into a sequence of code edits by using a linter to procedurally sample across the error-free insertions that can be used to sequentially write programs. It outputs edit sequences as text strings consisting of consecutive program diffs. To test LintSeq, we use it to refactor a dataset of instruction + program pairs into instruction + program-diff-sequence tuples. Then, we instruction finetune a series of smaller LLMs ranging from 2.6B to 14B parameters on both the re-factored and original versions of this dataset, comparing zero-shot performance on code synthesis benchmarks. We show that during repeated sampling, edit sequence finetuned models produce more diverse programs than baselines. This results in better inference-time scaling for benchmark coverage as a function of samples, i.e. the fraction of problems "pass@k" solved by any attempt given "k" tries. For example, on HumanEval pass@50, small LLMs finetuned on synthetic edit sequences are competitive with GPT-4 and outperform models finetuned on the baseline dataset by +20% (+/-3%) in absolute score. Finally, we also pretrain our own tiny LMs for code understanding. We show that finetuning tiny models on synthetic code edits results in state-of-the-art code synthesis for the on-device model class. Our 150M parameter edit sequence LM matches or outperforms code models with twice as many parameters, both with and without repeated sampling, including Codex and AlphaCode.
코드를 점진적으로 추가해나가는 형태의 데이터셋 구축. 코드에서 랜덤하게 한 줄을 삭제하고, 이 삭제로 인해 Linter에서 에러가 발생하는 라인들을 모두 삭제한 다음 반대 순서로 diff를 만드는 형태군요.
This paper describes a method for building a dataset of incrementally added code. The process involves randomly removing a line from the code, then deleting all lines that cause linter errors due to that removal. Finally, it creates a diff by reversing this sequence of deletions.
#code #synthetic-data
Scaling Parameter-Constrained Language Models with Quality Data
(Ernie Chang, Matteo Paltenghi, Yang Li, Pin-Jie Lin, Changsheng Zhao, Patrick Huber, Zechun Liu, Rastislav Rabatin, Yangyang Shi, Vikas Chandra)
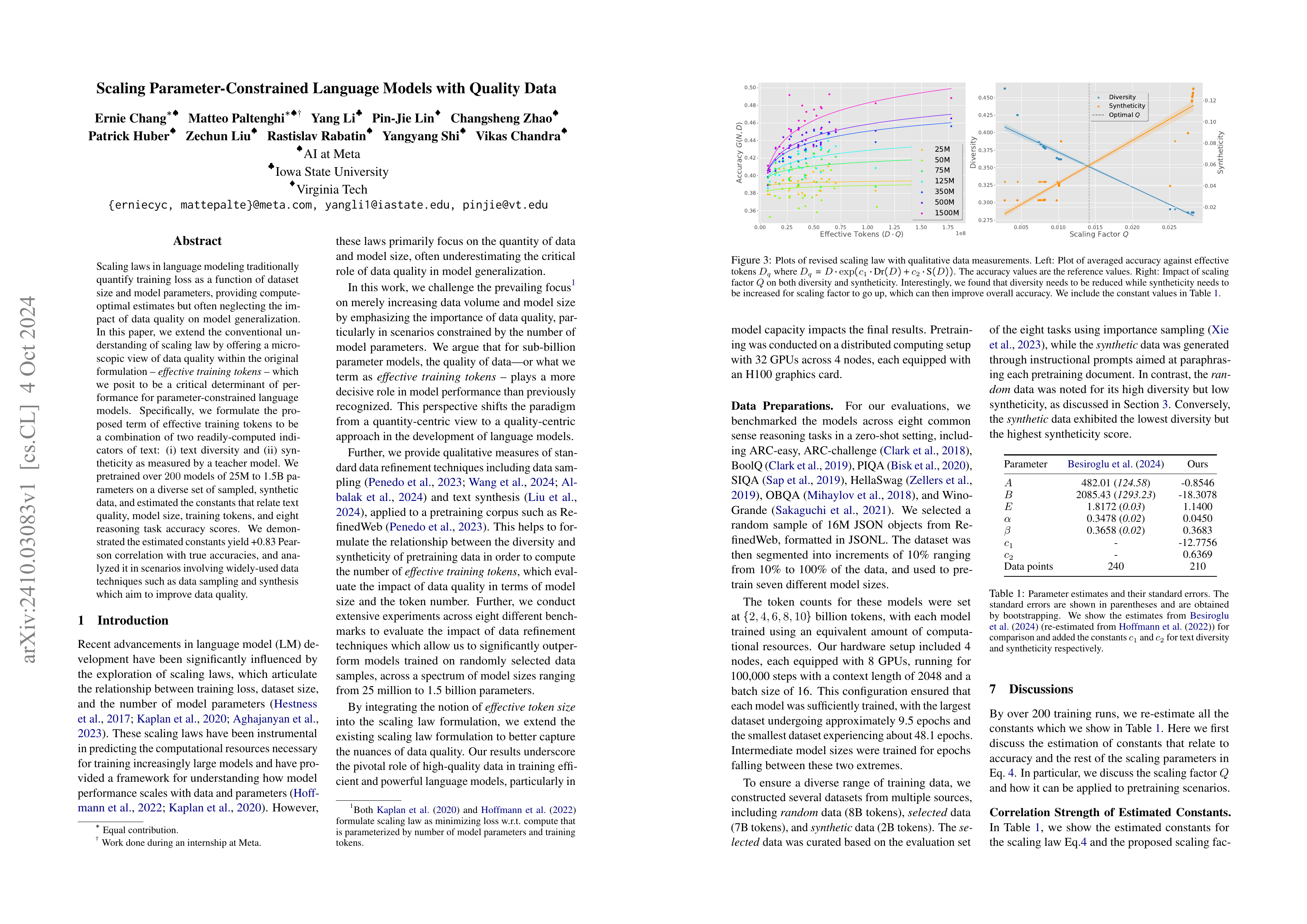
Scaling laws in language modeling traditionally quantify training loss as a function of dataset size and model parameters, providing compute-optimal estimates but often neglecting the impact of data quality on model generalization. In this paper, we extend the conventional understanding of scaling law by offering a microscopic view of data quality within the original formulation -- effective training tokens -- which we posit to be a critical determinant of performance for parameter-constrained language models. Specifically, we formulate the proposed term of effective training tokens to be a combination of two readily-computed indicators of text: (i) text diversity and (ii) syntheticity as measured by a teacher model. We pretrained over 200 models of 25M to 1.5B parameters on a diverse set of sampled, synthetic data, and estimated the constants that relate text quality, model size, training tokens, and eight reasoning task accuracy scores. We demonstrated the estimated constants yield +0.83 Pearson correlation with true accuracies, and analyzed it in scenarios involving widely-used data techniques such as data sampling and synthesis which aim to improve data quality.
데이터 품질을 고려한 Scaling Law를 추정. 데이터의 품질은 Diversity = gzip 압축률의 역수, Syntheticity = Perplexity의 역수로 추정했습니다.
관계가 아주 깨끗한 것 같지는 않지만 저자들의 결론은 모델이 작다면 Syntheticity, 즉 합성 데이터가 도움이 될 수 있지만 모델이 커질수록 학습 토큰의 양 자체가 중요해진다는 것이네요.
Estimating a scaling law that considers data quality. Data quality is estimated using diversity, which is the inverse of the gzip compression rate, and syntheticity, which is the inverse of perplexity.
While the relationship doesn't seem to be perfectly clear-cut, the authors' conclusion is that synthetic data (corresponds to syntheticity) can be beneficial for smaller models, but as models grow larger, the sheer quantity of training tokens becomes more important.
#synthetic-data #scaling-law
Autoregressive Large Language Models are Computationally Universal
(Dale Schuurmans, Hanjun Dai, Francesco Zanini)

We show that autoregressive decoding of a transformer-based language model can realize universal computation, without external intervention or modification of the model's weights. Establishing this result requires understanding how a language model can process arbitrarily long inputs using a bounded context. For this purpose, we consider a generalization of autoregressive decoding where, given a long input, emitted tokens are appended to the end of the sequence as the context window advances. We first show that the resulting system corresponds to a classical model of computation, a Lag system, that has long been known to be computationally universal. By leveraging a new proof, we show that a universal Turing machine can be simulated by a Lag system with 2027 production rules. We then investigate whether an existing large language model can simulate the behaviour of such a universal Lag system. We give an affirmative answer by showing that a single system-prompt can be developed for gemini-1.5-pro-001 that drives the model, under deterministic (greedy) decoding, to correctly apply each of the 2027 production rules. We conclude that, by the Church-Turing thesis, prompted gemini-1.5-pro-001 with extended autoregressive (greedy) decoding is a general purpose computer.
Extended Autoregressive Decoding이라는 N개 토큰의 Context Window에 대해 토큰을 생성한 다음 시퀀스 뒤에 붙이는 디코딩 알고리즘을 생각합니다. 그러면 이에 대응하는 Lag 시스템이라는, Prefix를 특정 심볼로 전환하는 알고리즘이 존재합니다. 그리고 Lag 시스템은 Universal Turing Machine을 시뮬레이션할 수 있습니다.
결과적으로 Autoregressive Decoding으로 Universal Turing Machine을 시뮬레이션하는 Lag 시스템을 시뮬레이션하는 것으로 LLM이 Universal Turing Machine이라는 것을 증명할 수 있습니다. Gemini로 해봤더니 됐다고 하네요.
좀 더 나아가서 사실 LM은 처음 시점부터 Univeral Turing Machine이고 Next Token Prediction을 통한 학습은 사람이 이해할 수 있는 인터페이스를 달아주는 과정인 것이 아닐까 하는 추측을 하는군요. 재미있습니다.
The paper considers an extended autoregressive decoding algorithm that generates tokens for an N-token context window and appends them to the end of the sequence. This corresponds to a Lag system, which is an algorithm that converts prefixes to specific symbols. It's shown that this Lag system can simulate a Universal Turing Machine.
Consequently, the authors prove that a Large Language Model (LLM) can be considered a Universal Turing Machine by demonstrating that autoregressive decoding can simulate a Lag system that simulates a Universal Turing Machine. They successfully tested this using Gemini.
Furthermore, the authors speculate that language models might actually be Universal Turing Machines from their initial state, and that the process of next-token prediction training merely provides a human-comprehensible interface. This is an intriguing idea.
#autoregressive-model #computation