



2024년 10월 23일

Altogether: Image Captioning via Re-aligning Alt-text
(Hu Xu, Po-Yao Huang, Xiaoqing Ellen Tan, Ching-Feng Yeh, Jacob Kahn, Christine Jou, Gargi Ghosh, Omer Levy, Luke Zettlemoyer, Wen-tau Yih, Shang-Wen Li, Saining Xie, Christoph Feichtenhofer)

This paper focuses on creating synthetic data to improve the quality of image captions. Existing works typically have two shortcomings. First, they caption images from scratch, ignoring existing alt-text metadata, and second, lack transparency if the captioners' training data (e.g. GPT) is unknown. In this paper, we study a principled approach Altogether based on the key idea to edit and re-align existing alt-texts associated with the images. To generate training data, we perform human annotation where annotators start with the existing alt-text and re-align it to the image content in multiple rounds, consequently constructing captions with rich visual concepts. This differs from prior work that carries out human annotation as a one-time description task solely based on images and annotator knowledge. We train a captioner on this data that generalizes the process of re-aligning alt-texts at scale. Our results show our Altogether approach leads to richer image captions that also improve text-to-image generation and zero-shot image classification tasks.
Alt 텍스트를 기반으로 개선된 캡션을 만드는 작업을 반복해서 캡션을 작성하는 방법. 사람을 통해 직접 데이터를 구축했군요. 웹 데이터의 좋은 점은 그 무궁무진한 다양성이라고 생각하는데 단순한 캡셔닝은 이 다양성을 떨어뜨릴 가능성이 있겠죠. Alt 텍스트를 활용하는 것은 그 점에서 좋은 접근이리라고 생각합니다.
Method for generating captions by iteratively refining captions starting from alt texts. They employed humans to create the dataset. I believe the great advantage of web data is its immense diversity. Simple captioning can reduce this diversity. In this regard, I think utilizing alt texts is a good approach.
#captioning #dataset #image-text
MiniPLM: Knowledge Distillation for Pre-Training Language Models
(Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, Minlie Huang)

Knowledge distillation (KD) is widely used to train small, high-performing student language models (LMs) using large teacher LMs. While effective in fine-tuning, KD during pre-training faces challenges in efficiency, flexibility, and effectiveness. Existing methods either incur high computational costs due to online teacher inference, require tokenization matching between teacher and student LMs, or risk losing the difficulty and diversity of the teacher-generated training data. To address these issues, we propose MiniPLM, a KD framework for pre-training LMs by refining the training data distribution with the teacher's knowledge. For efficiency, MiniPLM performs offline teacher LM inference, allowing KD for multiple student LMs without adding training-time costs. For flexibility, MiniPLM operates solely on the training corpus, enabling KD across model families. For effectiveness, MiniPLM leverages the differences between large and small LMs to enhance the difficulty and diversity of the training data, helping student LMs acquire versatile and sophisticated knowledge. Extensive experiments demonstrate that MiniPLM boosts the student LMs' performance on 9 widely used downstream tasks, improves the language modeling capabilities, and reduces pre-training computation. The benefit of MiniPLM extends to large pre-training scales, evidenced by the extrapolation of the scaling curves. Further analysis reveals that MiniPLM supports KD across model families and enhances the utilization of pre-training data. Our model, code, and data are available at https://github.com/thu-coai/MiniPLM.
LM에 대한 Knowledge Distillation 방법. Knowledge Distillation을 좀 더 쉽게 하려는 접근인데 결과적으로는 Teacher 모델과 레퍼런스 모델의 차이가 큰 샘플들을 샘플링하는 방법이군요. Learnability와 비슷한 접근 같네요. (https://arxiv.org/abs/2206.07137)
This paper presents a knowledge distillation method for LMs. It aims to simplify the knowledge distillation process, and the key technique involves sampling data points where there's a larger difference between the teacher and reference models. This approach seems similar to the concept of learnability. (https://arxiv.org/abs/2206.07137)
#distillation
Aligning Large Language Models via Self-Steering Optimization
(Hao Xiang, Bowen Yu, Hongyu Lin, Keming Lu, Yaojie Lu, Xianpei Han, Le Sun, Jingren Zhou, Junyang Lin)

Automated alignment develops alignment systems with minimal human intervention. The key to automated alignment lies in providing learnable and accurate preference signals for preference learning without human annotation. In this paper, we introduce Self-Steering Optimization (𝑆𝑆𝑂SSO), an algorithm that autonomously generates high-quality preference signals based on predefined principles during iterative training, eliminating the need for manual annotation. 𝑆𝑆𝑂SSO maintains the accuracy of signals by ensuring a consistent gap between chosen and rejected responses while keeping them both on-policy to suit the current policy model's learning capacity. 𝑆𝑆𝑂SSO can benefit the online and offline training of the policy model, as well as enhance the training of reward models. We validate the effectiveness of 𝑆𝑆𝑂SSO with two foundation models, Qwen2 and Llama3.1, indicating that it provides accurate, on-policy preference signals throughout iterative training. Without any manual annotation or external models, 𝑆𝑆𝑂SSO leads to significant performance improvements across six subjective or objective benchmarks. Besides, the preference data generated by 𝑆𝑆𝑂SSO significantly enhanced the performance of the reward model on Rewardbench. Our work presents a scalable approach to preference optimization, paving the way for more efficient and effective automated alignment.
규칙 기반 Alignment 방법인데 좋은 규칙에 대해서 생성된 응답과 나쁜 규칙에 대해 생성된 응답이 있을 때 좋은 규칙 프롬프트에 대해서는 좋은 규칙에 대해 생성된 응답을 선호하고, 나쁜 규칙 프롬프트에 대해서는 규칙 제시 없이 생성된 응답을 선호한다는 형태군요. 다른 프롬프트에 대한 응답을 가져와 섞는 방법이 생각나네요. (https://arxiv.org/abs/2409.13156)
This is a principle based alignment method. When there are responses generated based on good principles and bad principles, for prompts with good principles, it prefers responses generated from good principles. For prompts with bad principles, it prefers responses generated without any principles. This reminds me of the method where responses from different prompts are taken and mixed. (https://arxiv.org/abs/2409.13156)
#rlaif
TIPS: Text-Image Pretraining with Spatial Awareness
(Kevis-Kokitsi Maninis, Kaifeng Chen, Soham Ghosh, Arjun Karpur, Koert Chen, Ye Xia, Bingyi Cao, Daniel Salz, Guangxing Han, Jan Dlabal, Dan Gnanapragasam, Mojtaba Seyedhosseini, Howard Zhou, Andre Araujo)

While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
CLIP에 이미지 인코더에 대한 SSL을 추가했군요. 이미지-텍스트 생성 모델에 대해서 이미지에 대한 SSL을 추가하는 것도 재미있는 방향이겠죠.
They've added SSL to the image encoder of CLIP. It would be an interesting direction to apply image SSL objectives to image-text generative models as well.
#contrastive-learning #clip #image-text
Methods of improving LLM training stability
(Oleg Rybakov, Mike Chrzanowski, Peter Dykas, Jinze Xue, Ben Lanir)

Training stability of large language models(LLMs) is an important research topic. Reproducing training instabilities can be costly, so we use a small language model with 830M parameters and experiment with higher learning rates to force models to diverge. One of the sources of training instability is the growth of logits in attention layers. We extend the focus of the previous work and look not only at the magnitude of the logits but at all outputs of linear layers in the Transformer block. We observe that with a high learning rate the L2 norm of all linear layer outputs can grow with each training step and the model diverges. Specifically we observe that QKV, Proj and FC2 layers have the largest growth of the output magnitude. This prompts us to explore several options: 1) apply layer normalization not only after QK layers but also after Proj and FC2 layers too; 2) apply layer normalization after the QKV layer (and remove pre normalization). 3) apply QK layer normalization together with softmax capping. We show that with the last two methods we can increase learning rate by 1.5x (without model divergence) in comparison to an approach based on QK layer normalization only. Also we observe significant perplexity improvements for all three methods in comparison to the baseline model.
QK Norm 같은 트랜스포머 학습 안정성을 위한 테크닉들을 실험해봤군요. 저는 Softcapping과 Post Norm의 조합이 꽤 괜찮다고 생각합니다. 다만 이 조합은 실험에는 없네요.
They've experimented with various techniques for improving transformer training stability, such as QK Norm. I think the combination of softcapping and post-normalization could be quite effective. However, this specific combination wasn't tested in the paper.
#transformer
One-Step Diffusion Distillation through Score Implicit Matching
(Weijian Luo, Zemin Huang, Zhengyang Geng, J. Zico Kolter, Guo-jun Qi)
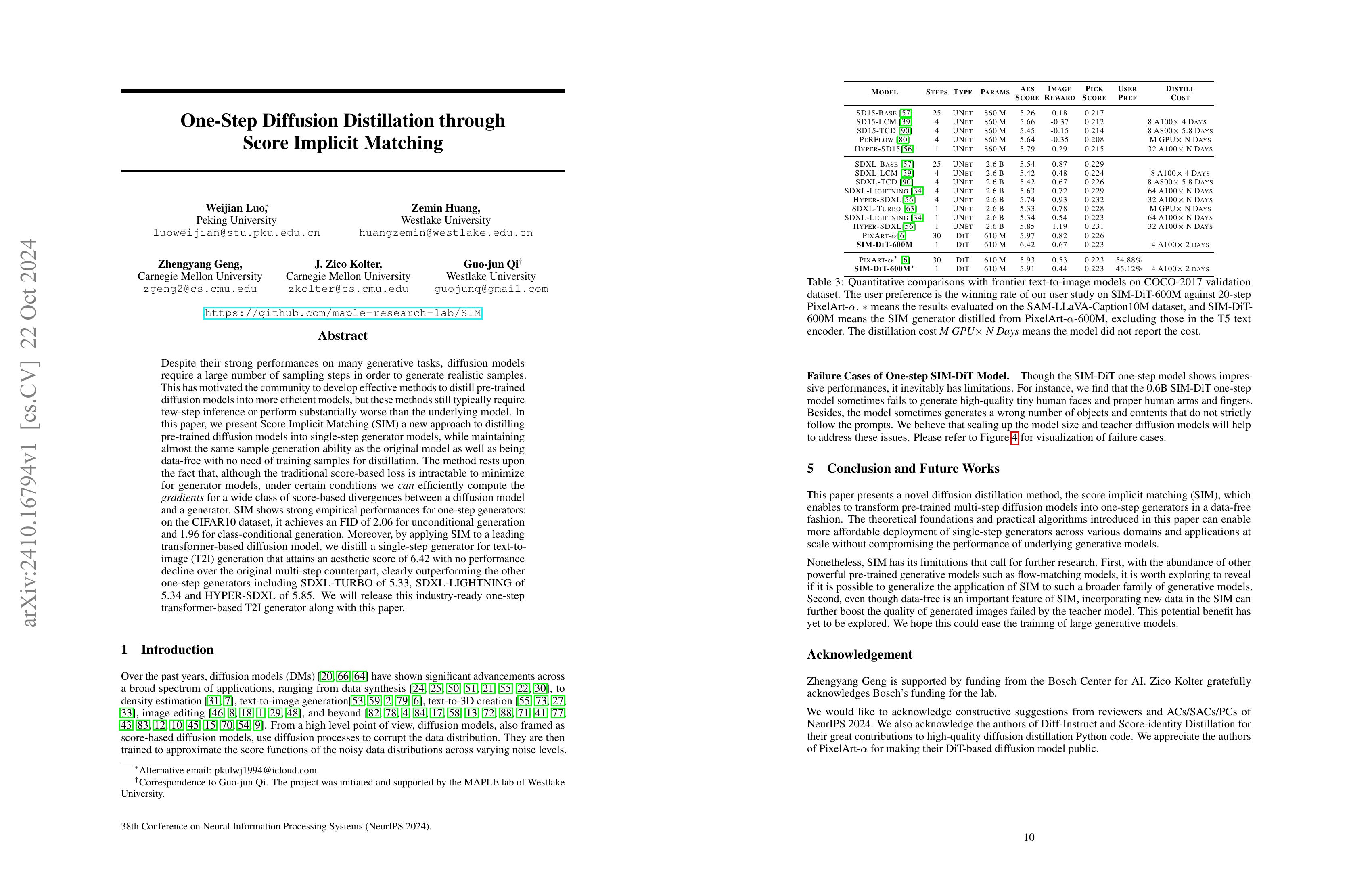
Despite their strong performances on many generative tasks, diffusion models require a large number of sampling steps in order to generate realistic samples. This has motivated the community to develop effective methods to distill pre-trained diffusion models into more efficient models, but these methods still typically require few-step inference or perform substantially worse than the underlying model. In this paper, we present Score Implicit Matching (SIM) a new approach to distilling pre-trained diffusion models into single-step generator models, while maintaining almost the same sample generation ability as the original model as well as being data-free with no need of training samples for distillation. The method rests upon the fact that, although the traditional score-based loss is intractable to minimize for generator models, under certain conditions we can efficiently compute the gradients for a wide class of score-based divergences between a diffusion model and a generator. SIM shows strong empirical performances for one-step generators: on the CIFAR10 dataset, it achieves an FID of 2.06 for unconditional generation and 1.96 for class-conditional generation. Moreover, by applying SIM to a leading transformer-based diffusion model, we distill a single-step generator for text-to-image (T2I) generation that attains an aesthetic score of 6.42 with no performance decline over the original multi-step counterpart, clearly outperforming the other one-step generators including SDXL-TURBO of 5.33, SDXL-LIGHTNING of 5.34 and HYPER-SDXL of 5.85. We will release this industry-ready one-step transformer-based T2I generator along with this paper.
1 step Generator에 대한 Diffusion Distillation. 이미지 생성 자체를 목표로 한다면 Autoregressive 모델은 Distill된 Diffusion 모델과 경쟁해야 하겠죠.
Diffusion distillation for a one-step generator. If image generation itself is the goal, autoregressive models will need to compete with distilled diffusion models.
#distillation #diffusion