



2024년 10월 22일

Granite 3.0 Language Models
(Granite Team, IBM)
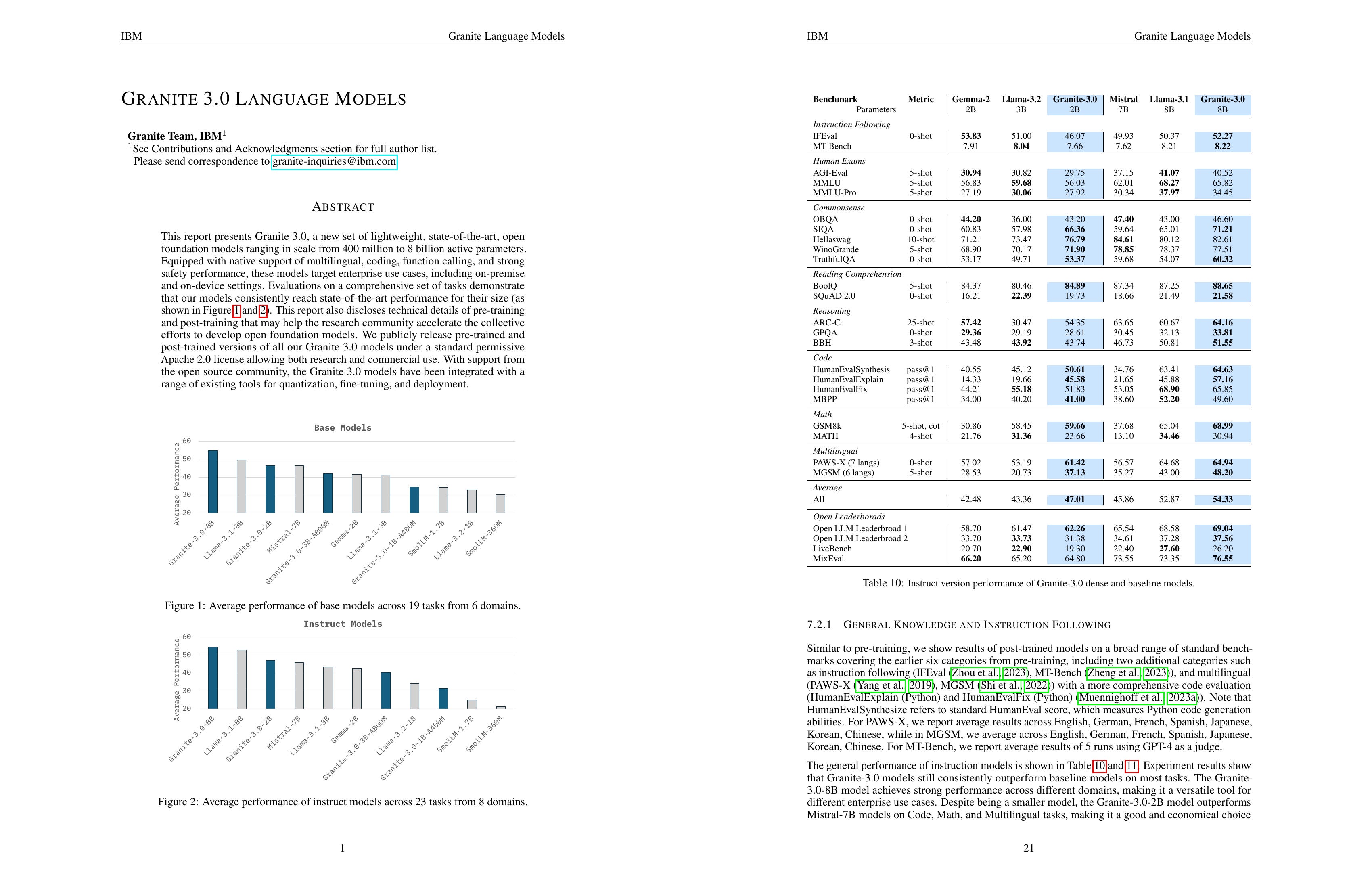
This report presents Granite 3.0, a new set of lightweight, state-of-the-art, open foundation models ranging in scale from 400 million to 8 billion active parameters. Equipped with native support of multilingual, coding, function calling, and strong safety performance, these models target enterprise use cases, including on-premise and on-device settings. Evaluations on a comprehensive set of tasks demonstrate that our models consistently reach state-of-the-art performance for their size (as shown in Figure 1 and 2). This report also discloses technical details of pre-training and post-training that may help the research community accelerate the collective efforts to develop open foundation models. We publicly release pre-trained and post-trained versions of all our Granite 3.0 models under a standard permissive Apache 2.0 license allowing both research and commercial use. With support from the open source community, the Granite 3.0 models have been integrated with a range of existing tools for quantization, fine-tuning, and deployment.
IBM의 LLM. Dense 2B, 8B 모델에 대해 12T 학습, 또는 Activated 400M/Weight 1B, Activated 800M/Weight 3B Dropless MoE 모델에 대해 10T 학습. µP, Power Scheduler (https://arxiv.org/abs/2408.13359) 사용. Multi Stage 학습이고 Instruction 데이터를 많이 썼네요. 데이터 비율 결정도 Objective를 설정해 탐색하는 방법을 사용했군요.
정렬 단계에서도 SFT/PPO 외에 Best of N, BRAIn (https://arxiv.org/abs/2402.02479), Reward Model 앙상블, 모델 병합 등 이런 저런 방법을 많이 썼네요. 재미있습니다.
IBM's LLM. Dense 2B and 8B models trained on 12T tokens, or Dropless MoE models with 400M activated / 1B weights and 800M activated / 3B weights trained on 10T tokens. They used µP and Power Scheduler (https://arxiv.org/abs/2408.13359). Multi-stage training was employed, with a large amount of instruction data. The data ratio was determined through objective-based search.
For the alignment stages, they used various methods in addition to SFT and PPO, including Best of N, BRAIn (https://arxiv.org/abs/2402.02479), reward model ensemble, and model merging. Quite interesting.
#llm #alignment
Truncated Consistency Models
(Sangyun Lee, Yilun Xu, Tomas Geffner, Giulia Fanti, Karsten Kreis, Arash Vahdat, Weili Nie)

Consistency models have recently been introduced to accelerate sampling from diffusion models by directly predicting the solution (i.e., data) of the probability flow ODE (PF ODE) from initial noise. However, the training of consistency models requires learning to map all intermediate points along PF ODE trajectories to their corresponding endpoints. This task is much more challenging than the ultimate objective of one-step generation, which only concerns the PF ODE's noise-to-data mapping. We empirically find that this training paradigm limits the one-step generation performance of consistency models. To address this issue, we generalize consistency training to the truncated time range, which allows the model to ignore denoising tasks at earlier time steps and focus its capacity on generation. We propose a new parameterization of the consistency function and a two-stage training procedure that prevents the truncated-time training from collapsing to a trivial solution. Experiments on CIFAR-10 and ImageNet 64×64 datasets show that our method achieves better one-step and two-step FIDs than the state-of-the-art consistency models such as iCT-deep, using more than 2× smaller networks. Project page:
https://truncated-cm.github.io/
Consistency Model의 학습의 난점은 노이즈 -> 데이터라는 생성 목표와 중간 지점 -> 데이터라는 디노이징 목표가 같이 학습 되기 때문이라는 아이디어. 따라서 t를 제약해 생성 목표에 중점을 두는 것으로 성능을 개선할 수 있다는 아이디어. 다만 t를 제약하면 경계 조건이 사라져 붕괴가 일어나기 때문에 t가 제약된 상황에서 경계 조건을 설정해줍니다.
Consistency Model에 대해서는 학습 안정성에 대한 이야기가 많이 나오는군요. 무언가 GAN 시절의 추억이 떠오르고 그렇네요.
The key idea is that the difficulty in training Consistency Models stems from simultaneously learning both the generative objective (noise -> data) and the denoising objective (intermediate points -> data). Therefore, performance can be improved by restricting t and focusing on the generative objective. However, restricting t removes boundary conditions, leading to model collapse. To address this, novel boundary conditions are designed for restricted t.
Regarding Consistency Models, there's a lot of discussion about training stability. It somewhat reminds me of the GAN era.
#diffusion
Baichuan Alignment Technical Report
(Mingan Lin, Fan Yang, Yanjun Shen, Haoze Sun, Tianpeng Li, Tao Zhang, Chenzheng Zhu, Tao Zhang, Miao Zheng, Xu Li, Yijie Zhou, Mingyang Chen, Yanzhao Qin, Youquan Li, Hao Liang, Fei Li, Yadong Li, Mang Wang, Guosheng Dong, Kun Fang, Jianhua Xu, Bin Cui, Wentao Zhang, Zenan Zhou, Weipeng Chen)

We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
Baichuan의 정렬 과정에 대한 리포트군요. GRPO 사용, Prompt Augmentation, 모델 병합 등.
This is a report on Baichuan's alignment processes. They utilized GRPO, prompt augmentation, and model merging techniques, among others.
#alignment
Chasing Random: Instruction Selection Strategies Fail to Generalize
(Harshita Diddee, Daphne Ippolito)

Prior work has shown that language models can be tuned to follow user instructions using only a small set of high-quality instructions. This has accelerated the development of methods that filter a large, noisy instruction-tuning datasets down to high-quality subset which works just as well. However, typically, the performance of these methods is not demonstrated across a uniform experimental setup and thus their generalization capabilities are not well established. In this work, we analyze popular selection strategies across different source datasets, selection budgets and evaluation benchmarks: Our results indicate that selection strategies generalize poorly, often failing to consistently outperform even random baselines. We also analyze the cost-performance trade-offs of using data selection. Our findings reveal that data selection can often exceed the cost of fine-tuning on the full dataset, yielding only marginal and sometimes no gains compared to tuning on the full dataset or a random subset.
Instruction 데이터 선택 방법이 다양한 과제나 데이터셋에 대해 랜덤 선택보다도 (특히 비용까지 고려한다면) 안정적으로 더 나은 결과를 얻기 어렵다는 분석. 비슷한 결과가 얼마 전에도 나왔었죠. (https://arxiv.org/abs/2410.09335) 복잡하고 정교한 방법이 랜덤보다 확연히 우수하지 않은 것도 전형적인 패턴이긴 합니다.
This analysis shows that sophisticated data selection methods for instruction tuning struggle to consistently outperform random sampling across various tasks and datasets, especially when considering cost-effectiveness. Similar results were published recently (https://arxiv.org/abs/2410.09335). It's a typical pattern that complex and elaborate methods often fail to significantly surpass simple random approaches.
#alignment #dataset
On Designing Effective RL Reward at Training Time for LLM Reasoning
(Jiaxuan Gao, Shusheng Xu, Wenjie Ye, Weilin Liu, Chuyi He, Wei Fu, Zhiyu Mei, Guangju Wang, Yi Wu)

Reward models have been increasingly critical for improving the reasoning capability of LLMs. Existing research has shown that a well-trained reward model can substantially improve model performances at inference time via search. However, the potential of reward models during RL training time still remains largely under-explored. It is currently unclear whether these reward models can provide additional training signals to enhance the reasoning capabilities of LLMs in RL training that uses sparse success rewards, which verify the correctness of solutions. In this work, we evaluate popular reward models for RL training, including the Outcome-supervised Reward Model (ORM) and the Process-supervised Reward Model (PRM), and train a collection of LLMs for math problems using RL by combining these learned rewards with success rewards. Surprisingly, even though these learned reward models have strong inference-time performances, they may NOT help or even hurt RL training, producing worse performances than LLMs trained with the success reward only. Our analysis reveals that an LLM can receive high rewards from some of these reward models by repeating correct but unnecessary reasoning steps, leading to a severe reward hacking issue. Therefore, we introduce two novel reward refinement techniques, including Clipping and Delta. The key idea is to ensure the accumulative reward of any reasoning trajectory is upper-bounded to keep a learned reward model effective without being exploited. We evaluate our techniques with multiple reward models over a set of 1.5B and 7B LLMs on MATH and GSM8K benchmarks and demonstrate that with a carefully designed reward function, RL training without any additional supervised tuning can improve all the evaluated LLMs, including the state-of-the-art 7B LLM Qwen2.5-Math-7B-Instruct on MATH and GSM8K benchmarks.
Process Reward Model을 사용해서 RL을 진행했을 때 발생한 Reward Hacking 문제에 대한 경험. 문제 해결에 도움이 되지 않는 문장들을 채워넣는 패턴이 발생했다고 하네요. 대응 방법 중 하나는 생성한 문장에 의해 문제 해결에 진전이 발생하는지를 측정하는 것. Process Reward는 Advantage여야 한다는 주장이 떠오르는군요. (https://arxiv.org/abs/2410.08146)
This paper discusses the experience of reward hacking when using a process reward model for RL. They observed a pattern where the model learned to generate sentences that didn't contribute to problem-solving. One proposed method to address this issue is to measure whether the generated sentences actually lead to progress in solving the problem. This reminds me of an earlier argument that process rewards should be advantage. (https://arxiv.org/abs/2410.08146)
#rl
Keep Guessing? When Considering Inference Scaling, Mind the Baselines
(Gal Yona, Or Honovich, Omer Levy, Roee Aharoni)

Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains k answers by using only 10 model samples and similarly guessing the remaining k-10 attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.
Inference Scaling을 측정할 때 학습 셋에 자주 등장한 Top K개의 정답을 사용하는 베이스라인으로 보정해야 한다는 주장. 굉장히 중요한 지적 같네요.
This paper argues that when measuring inference scaling, we should use a baseline that incorporates the top K most frequent answers from the training set. This seems to be a very important observation.
#search
Beyond Filtering: Adaptive Image-Text Quality Enhancement for MLLM Pretraining
(Han Huang, Yuqi Huo, Zijia Zhao, Haoyu Lu, Shu Wu, Bingning Wang, Qiang Liu, Weipeng Chen, Liang Wang)

Multimodal large language models (MLLMs) have made significant strides by integrating visual and textual modalities. A critical factor in training MLLMs is the quality of image-text pairs within multimodal pretraining datasets. However, de facto filter-based data quality enhancement paradigms often discard a substantial portion of high-quality image data due to inadequate semantic alignment between images and texts, leading to inefficiencies in data utilization and scalability. In this paper, we propose the Adaptive Image-Text Quality Enhancer (AITQE), a model that dynamically assesses and enhances the quality of image-text pairs. AITQE employs a text rewriting mechanism for low-quality pairs and incorporates a negative sample learning strategy to improve evaluative capabilities by integrating deliberately selected low-quality samples during training. Unlike prior approaches that significantly alter text distributions, our method minimally adjusts text to preserve data volume while enhancing quality. Experimental results demonstrate that AITQE surpasses existing methods on various benchmark, effectively leveraging raw data and scaling efficiently with increasing data volumes. We hope our work will inspire future works. The code and model are available at: https://github.com/hanhuang22/AITQE.
이미지-텍스트 데이터의 품질 평가와 캡션 재작성을 수행하는 모델 개발. 품질이 높은 데이터는 그대로 사용하고 품질이 낮은 경우 캡션을 재작성한다는 아이디어네요. 캡션 재작성은 이제 기본적인 도구가 되었는데 이를 잘 하는 것이 중요한 예술이 되었다는 느낌이네요.
This paper presents the development of a model that assesses the quality of image-text data and performs recaptioning. The idea is to use high-quality data as-is while recaptioning low-quality data. It seems that recaptioning has now become a fundamental tool, and the art of doing it well has become an important skill.
#multimodal #captioning #dataset
CartesianMoE: Boosting Knowledge Sharing among Experts via Cartesian Product Routing in Mixture-of-Experts
(Zhenpeng Su, Xing Wu, Zijia Lin, Yizhe Xiong, Minxuan Lv, Guangyuan Ma, Hui Chen, Songlin Hu, Guiguang Ding)

Large language models (LLM) have been attracting much attention from the community recently, due to their remarkable performance in all kinds of downstream tasks. According to the well-known scaling law, scaling up a dense LLM enhances its capabilities, but also significantly increases the computational complexity. Mixture-of-Experts (MoE) models address that by allowing the model size to grow without substantially raising training or inference costs. Yet MoE models face challenges regarding knowledge sharing among experts, making their performance somehow sensitive to routing accuracy. To tackle that, previous works introduced shared experts and combined their outputs with those of the top K routed experts in an addition manner. In this paper, inspired by collective matrix factorization to learn shared knowledge among data, we propose CartesianMoE, which implements more effective knowledge sharing among experts in more like a multiplication manner. Extensive experimental results indicate that CartesianMoE outperforms previous MoE models for building LLMs, in terms of both perplexity and downstream task performance. And we also find that CartesianMoE achieves better expert routing robustness.
작은 Expert를 여러 개 사용하는 것이 대세이니, 여러 개를 한 번에 사용하는 대신 두 단계로 나눠 사용하는 것도 생각해 볼 만하겠네요.
Since using multiple small experts has become the trend, it's worth considering using them in two stages rather than all at once.
#moe
Elucidating the design space of language models for image generation
(Xuantong Liu, Shaozhe Hao, Xianbiao Qi, Tianyang Hu, Jun Wang, Rong Xiao, Yuan Yao)
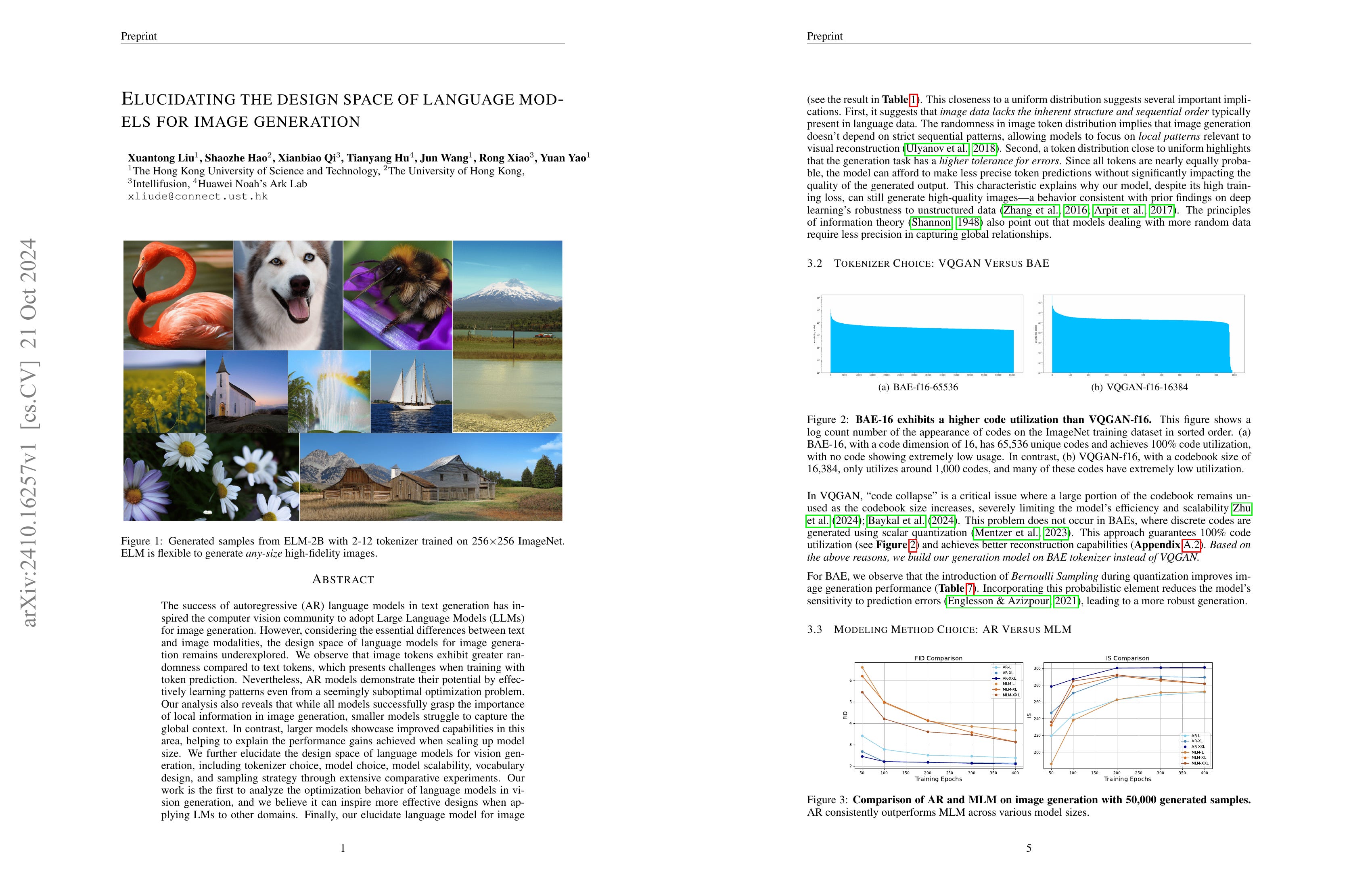
The success of autoregressive (AR) language models in text generation has inspired the computer vision community to adopt Large Language Models (LLMs) for image generation. However, considering the essential differences between text and image modalities, the design space of language models for image generation remains underexplored. We observe that image tokens exhibit greater randomness compared to text tokens, which presents challenges when training with token prediction. Nevertheless, AR models demonstrate their potential by effectively learning patterns even from a seemingly suboptimal optimization problem. Our analysis also reveals that while all models successfully grasp the importance of local information in image generation, smaller models struggle to capture the global context. In contrast, larger models showcase improved capabilities in this area, helping to explain the performance gains achieved when scaling up model size. We further elucidate the design space of language models for vision generation, including tokenizer choice, model choice, model scalability, vocabulary design, and sampling strategy through extensive comparative experiments. Our work is the first to analyze the optimization behavior of language models in vision generation, and we believe it can inspire more effective designs when applying LMs to other domains. Finally, our elucidated language model for image generation, termed as ELM, achieves state-of-the-art performance on the ImageNet 256*256 benchmark. The code is available at https://github.com/Pepperlll/LMforImageGeneration.git.
VQ vs Binary Quantization, AR vs MLM, Binary Quantization을 쪼개 Factorize된 코드를 예측하는 방법 등에 대한 비교 실험이군요. 이미지 생성 측면에서는 디자인 공간이 여전히 넓어서 그 부분에 대한 증거를 수집하는 것이 굉장히 중요한 작업이라는 생각을 합니다.
This paper compares experiments on VQ vs. binary quantization, AR vs. MLM, and methods for predicting factorized codes by splitting binary quantization. I believe that the design space for image generation is still vast, making it extremely important to gather evidence about various aspects of this space.
#vq #autoregressive-model #image-generation
InternLM2.5-StepProver: Advancing Automated Theorem Proving via Expert Iteration on Large-Scale LEAN Problems
(Zijian Wu, Suozhi Huang, Zhejian Zhou, Huaiyuan Ying, Jiayu Wang, Dahua Lin, Kai Chen)

Large Language Models (LLMs) have emerged as powerful tools in mathematical theorem proving, particularly when utilizing formal languages such as LEAN. The major learning paradigm is expert iteration, which necessitates a pre-defined dataset comprising numerous mathematical problems. In this process, LLMs attempt to prove problems within the dataset and iteratively refine their capabilities through self-training on the proofs they discover. We propose to use large scale LEAN problem datasets Lean-workbook for expert iteration with more than 20,000 CPU days. During expert iteration, we found log-linear trends between solved problem amount with proof length and CPU usage. We train a critic model to select relatively easy problems for policy models to make trials and guide the model to search for deeper proofs. InternLM2.5-StepProver achieves open-source state-of-the-art on MiniF2F, Lean-Workbook-Plus, ProofNet, and Putnam benchmarks. Specifically, it achieves a pass of 65.9% on the MiniF2F-test and proves (or disproves) 17.0% of problems in Lean-Workbook-Plus which shows a significant improvement compared to only 9.5% of problems proved when Lean-Workbook-Plus was released. We open-source our models and searched proofs at https://github.com/InternLM/InternLM-Math and https://huggingface.co/datasets/internlm/Lean-Workbook.
Lean Workbook의 주장들을 기반으로 대규모 Expert Iteration을 진행해서 모델의 증명 능력 향상 시도를 했군요. CPU 시간으로 측정했을 때 1.5% 정도만이 실제로 유의미한 증명으로 이어졌고 98.5%는 결과로 이어지지 않았다고 하네요. 더 효율적인 탐색이 필요하다는 의미일 듯 합니다.
They attempted to enhance the model's proving capabilities by conducting large-scale Expert Iteration based on the Lean Workbook problems. Measuring by CPU time, only about 1.5% resulted in meaningful proofs, while 98.5% did not lead to any results. This suggests that more efficient search methods are needed.
#math #search
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
(Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, Graham Neubig)

Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
기계 번역 기반 Multilingual Multimodal Instruction + 문화적 특성을 고려해 샘플링한 이미지에 대해 생성한 캡션과 Instruction으로 구성한 데이터셋과 벤치마크군요.
This paper presents a dataset and benchmark consisting of multilingual multimodal instructions based on machine translation, along with captions and instructions generated for images sampled with cultural characteristics in mind.
#multimodal #multilingual #dataset
Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Composite Spatial Reasoning
(Yihong Tang, Ao Qu, Zhaokai Wang, Dingyi Zhuang, Zhaofeng Wu, Wei Ma, Shenhao Wang, Yunhan Zheng, Zhan Zhao, Jinhua Zhao)

Vision language models (VLMs) have demonstrated impressive performance across a wide range of downstream tasks. However, their proficiency in spatial reasoning remains limited, despite its crucial role in tasks involving navigation and interaction with physical environments. Specifically, much of the spatial reasoning in these tasks occurs in two-dimensional (2D) environments, and our evaluation reveals that state-of-the-art VLMs frequently generate implausible and incorrect responses to composite spatial reasoning problems, including simple pathfinding tasks that humans can solve effortlessly at a glance. To address this, we explore an effective approach to enhance 2D spatial reasoning within VLMs by training the model on basic spatial capabilities. We begin by disentangling the key components of 2D spatial reasoning: direction comprehension, distance estimation, and localization. Our central hypothesis is that mastering these basic spatial capabilities can significantly enhance a model's performance on composite spatial tasks requiring advanced spatial understanding and combinatorial problem-solving. To investigate this hypothesis, we introduce Sparkle, a framework that fine-tunes VLMs on these three basic spatial capabilities by synthetic data generation and targeted supervision to form an instruction dataset for each capability. Our experiments demonstrate that VLMs fine-tuned with Sparkle achieve significant performance gains, not only in the basic tasks themselves but also in generalizing to composite and out-of-distribution spatial reasoning tasks (e.g., improving from 13.5% to 40.0% on the shortest path problem). These findings underscore the effectiveness of mastering basic spatial capabilities in enhancing composite spatial problem-solving, offering insights for improving VLMs' spatial reasoning capabilities.
기본적인 공간적 추론 과제를 통해 모델을 학습시키면 복합적인 공간적 추론이 필요한 과제에 대한 성능이 향상된다는 결과. 멀티모달 모델의 학습에는 모달리티 내의 다양한 구조를 추출할 수 있도록 데이터를 설계하는 것이 중요하지 않나 싶습니다.
This study shows that training models on basic spatial reasoning tasks improves their performance on tasks requiring complex spatial reasoning. It seems that when training multimodal models, it's crucial to design data that can extract various structures within each modality.
#multimodal
ToW: Thoughts of Words Improve Reasoning in Large Language Models
(Zhikun Xu, Ming Shen, Jacob Dineen, Zhaonan Li, Xiao Ye, Shijie Lu, Aswin RRV, Chitta Baral, Ben Zhou)

We introduce thoughts of words (ToW), a novel training-time data-augmentation method for next-word prediction. ToW views next-word prediction as a core reasoning task and injects fine-grained thoughts explaining what the next word should be and how it is related to the previous contexts in pre-training texts. Our formulation addresses two fundamental drawbacks of existing next-word prediction learning schemes: they induce factual hallucination and are inefficient for models to learn the implicit reasoning processes in raw texts. While there are many ways to acquire such thoughts of words, we explore the first step of acquiring ToW annotations through distilling from larger models. After continual pre-training with only 70K ToW annotations, we effectively improve models' reasoning performances by 7% to 9% on average and reduce model hallucination by up to 10%. At the same time, ToW is entirely agnostic to tasks and applications, introducing no additional biases on labels or semantics.
다음 단어 예측을 위한 추론 과정을 생성하기 위한 방법. 이전 문맥을 주고 다음 단어가 무엇일지 추론한 다음 단어를 예측하고, 예측 결과와 텍스트를 비교해 필터링하는 방법입니다. 이런 행간 생성에는 계속 관심이 가네요. GPT-4를 써서 생성한 것이라 좀 아쉽긴 합니다만.
This paper presents a method for generating reasoning processes to predict the next word. The model is given the previous context and asked to reason about what the next word might be, then predict that word. The results are then filtered by comparing the predicted words with the actual text. I'm always interested in methods for generating content between the lines. It would be better if the result does not depend on GPT-4.
#reasoning #synthetic-data