



2024년 10월 1일

MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
(Haotian Zhang, Mingfei Gao, Zhe Gan, Philipp Dufter, Nina Wenzel, Forrest Huang, Dhruti Shah, Xianzhi Du, Bowen Zhang, Yanghao Li, Sam Dodge, Keen You, Zhen Yang, Aleksei Timofeev, Mingze Xu, Hong-You Chen, Jean-Philippe Fauconnier, Zhengfeng Lai, Haoxuan You, Zirui Wang, Afshin Dehghan, Peter Grasch, Yinfei Yang)

We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
MM1.5. MM1에 (https://arxiv.org/abs/2403.09611) 이어 Ablation이 꽤 상세하군요. 이미지 그리드를 이미지 종횡비에 따라 바꾼다거나 (Dynamic Splitting) OCR 데이터와 고해상도 학습의 효과 등에 대한 실험을 진행했습니다.
MM1.5. Like MM1 (https://arxiv.org/abs/2403.09611) they shows quite detailed ablation studies. They conducted experiments on various modeling choices, such as dynamic splitting which adjusts image grid based on aspect ratios, and the effects of using OCR data and high-resolution training.
#vision-language
The Perfect Blend: Redefining RLHF with Mixture of Judges
(Tengyu Xu, Eryk Helenowski, Karthik Abinav Sankararaman, Di Jin, Kaiyan Peng, Eric Han, Shaoliang Nie, Chen Zhu, Hejia Zhang, Wenxuan Zhou, Zhouhao Zeng, Yun He, Karishma Mandyam, Arya Talabzadeh, Madian Khabsa, Gabriel Cohen, Yuandong Tian, Hao Ma, Sinong Wang, Han Fang)

Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to challenges of reward hacking and extreme multi-objective optimization (i.e., trade-off of multiple and/or sometimes conflicting objectives). Applying RLHF for MTL currently requires careful tuning of the weights for reward model and data combinations. This is often done via human intuition and does not generalize. In this work, we introduce a novel post-training paradigm which we called Constrained Generative Policy Optimization (CGPO). The core of CGPO is Mixture of Judges (MoJ) with cost-efficient constrained policy optimization with stratification, which can identify the perfect blend in RLHF in a principled manner. It shows strong empirical results with theoretical guarantees, does not require extensive hyper-parameter tuning, and is plug-and-play in common post-training pipelines. Together, this can detect and mitigate reward hacking behaviors while reaching a pareto-optimal point across an extremely large number of objectives. Our empirical evaluations demonstrate that CGPO significantly outperforms standard RLHF algorithms like PPO and DPO across various tasks including general chat, STEM questions, instruction following, and coding. Specifically, CGPO shows improvements of 7.4% in AlpacaEval-2 (general chat), 12.5% in Arena-Hard (STEM & reasoning), and consistent gains in other domains like math and coding. Notably, PPO, while commonly used, is prone to severe reward hacking in popular coding benchmarks, which CGPO successfully addresses. This breakthrough in RLHF not only tackles reward hacking and extreme multi-objective optimization challenges but also advances the state-of-the-art in aligning general-purpose LLMs for diverse applications.
현재 RLHF의 난점을 Multitask의 측면에서 생각했네요. Multitask에 대한 Reward Signal을 주어야 한다는 것과 이를 통해 RLHF를 진행해야 하는 것이 난이도를 높인다는 것입니다.
이에 대한 대응 방법으로 제약 조건을 부과하는 방법을 고안했네요. 예컨대 수학 문제라면 정답이 맞아야 한다는 것이 제약 조건이 되는 것이죠. 이에 더해 Reward Score를 캘리브레이션하는 방법을 설계했습니다.
그리고 프롬프트를 범주로 나눈 다음 각 카테고리에 대해 적합한 Judge를 적용하고 각 과제에 대한 그래디언트를 결합해 RLHF를 진행하는 형태입니다. 과제에 따라 KL Penalty 같은 하이퍼파라미터에도 차이를 줬군요.
Llama 3에서 다양한 과제에 대해 범주를 나눠 Preference를 수집하는 작업을 진행했었으니 그런 범주를 활용하는 방법을 생각하는 것도 자연스러운 것 같네요.
This paper approaches the current challenges of RLHF from the aspect of multitask learning. The difficulty lies in providing reward signals for multitask scenarios and then conducting RLHF based on these signals.
To address this issue, the authors devised a method that imposes constraints on the RLHF optimization process. For example, in mathematical problems, the constraint would be that the answer must be correct. Additionally, they designed a method to calibrate reward scores.
The approach then categorizes prompts and applies appropriate judges to each category. RLHF is then performed by combining the gradients from each task. Also, they varied hyperparameters like the KL penalty for different tasks.
Given that Llama 3 collected preferences for various tasks and categorized them, it seems natural to utilize such categorical structures.
#rlhf #multitask
Law of the Weakest Link: Cross Capabilities of Large Language Models
(Ming Zhong, Aston Zhang, Xuewei Wang, Rui Hou, Wenhan Xiong, Chenguang Zhu, Zhengxing Chen, Liang Tan, Chloe Bi, Mike Lewis, Sravya Popuri, Sharan Narang, Melanie Kambadur, Dhruv Mahajan, Sergey Edunov, Jiawei Han, Laurens van der Maaten)
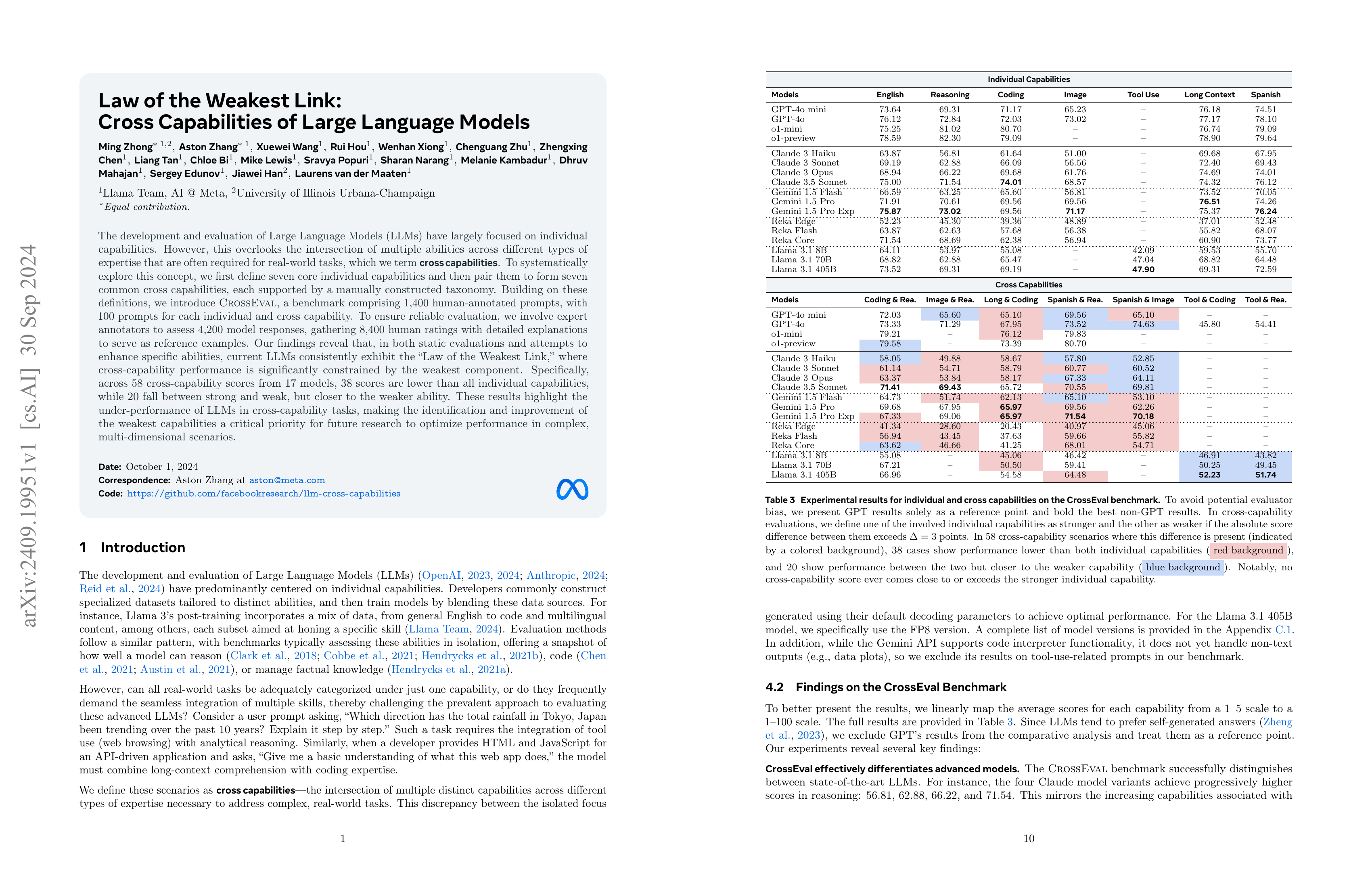
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
추론이나 코딩 같은 개별 능력들과 두 가지 능력이 동시에 필요한 과제들을 통한 벤치마크. 능력의 조합이 필요한 경우 개별 능력에 대한 성능보다 성능이 낮거나 혹은 두 능력 중 모델이 약한 능력의 성능과 비슷한 성능이 나온다는 것이 주된 발견입니다. 이런 능력의 결합 문제에 대한 지적 뿐만 아니라 벤치마크 자체로서도 흥미롭네요.
This paper presents a benchmark that evaluates both individual capabilities like reasoning and coding, as well as tasks that require a combination of two capabilities. The main finding is that when a combination of capabilities is required, the model's performance is either lower than its performance on individual capabilities or similar to its performance on the weaker of the two capabilities. Beside of problem of combining capabilities, and the benchmark itself is also interesting for model evaluation.
#llm #benchmark
Scaling Optimal LR Across Token Horizon
(Johan Bjorck, Alon Benhaim, Vishrav Chaudhary, Furu Wei, Xia Song)

State-of-the-art LLMs are powered by scaling -- scaling model size, dataset size and cluster size. It is economically infeasible to extensively tune hyperparameter for the largest runs. Instead, approximately optimal hyperparameters must be inferred or \textit{transferred} from smaller experiments. Hyperparameter transfer across model sizes has been studied in Yang et al. However, hyperparameter transfer across dataset size -- or token horizon -- has not been studied yet. To remedy this we conduct a large scale empirical study on how optimal learning rate (LR) depends on token horizon in LLM training. We first demonstrate that the optimal LR changes significantly with token horizon -- longer training necessitates smaller LR. Secondly we demonstrate the the optimal LR follows a scaling law, and that the optimal LR for longer horizons can be accurately estimated from shorter horizons via our scaling laws. We also provide a rule-of-thumb for transferring LR across token horizons with zero overhead over current practices. Lastly we provide evidence that LLama-1 used too high LR, and estimate the performance hit from this. We thus argue that hyperparameter transfer across data size is an important and overlooked component of LLM training.
요즘 이야기가 나오는 학습 길이에 따라 LR이 달라져야 하는가에 대한 연구. (https://arxiv.org/abs/2408.13359, https://arxiv.org/abs/2409.15156) 여기서도 학습량이 증가할수록 최적 LR이 좌측으로 이동한다는 것을 발견했네요.
이 문제에 대한 대응 방법은 학습 길이에 따른 최적 LR의 Scaling Law를 추정하는 것. 아이러니하지만 가장 경험적인 규칙인 Scaling Law가 지금은 가장 신뢰로운 도구라는 것을 시사하는 듯 하네요. 이런 형태의 Hyperparameter Scaling Law는 DeepSeek 등에서 시도했었는데 (https://arxiv.org/abs/2401.02954) 꽤 좋은 통찰력이었던 것 같습니다.
This is a study on whether the learning rate (LR) should change according to training length, a topic of recent discussion. (https://arxiv.org/abs/2408.13359, https://arxiv.org/abs/2409.15156) This paper also found that the optimal LR shifts to the left as the duration of training increases.
The approach to address this issue is to estimate the scaling law of optimal LR in relation to training length. Ironically, this suggests that the scaling law, which is one of the most empirical rules, is currently the most reliable tool for these kinds of problems. This form of hyperparameter scaling law was previously attempted by DeepSeek and others (https://arxiv.org/abs/2401.02954), and it seems to have been quite an insightful approach.
#hyperparameter #scaling-law
Hyper-Connections
(Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, Xun Zhou)
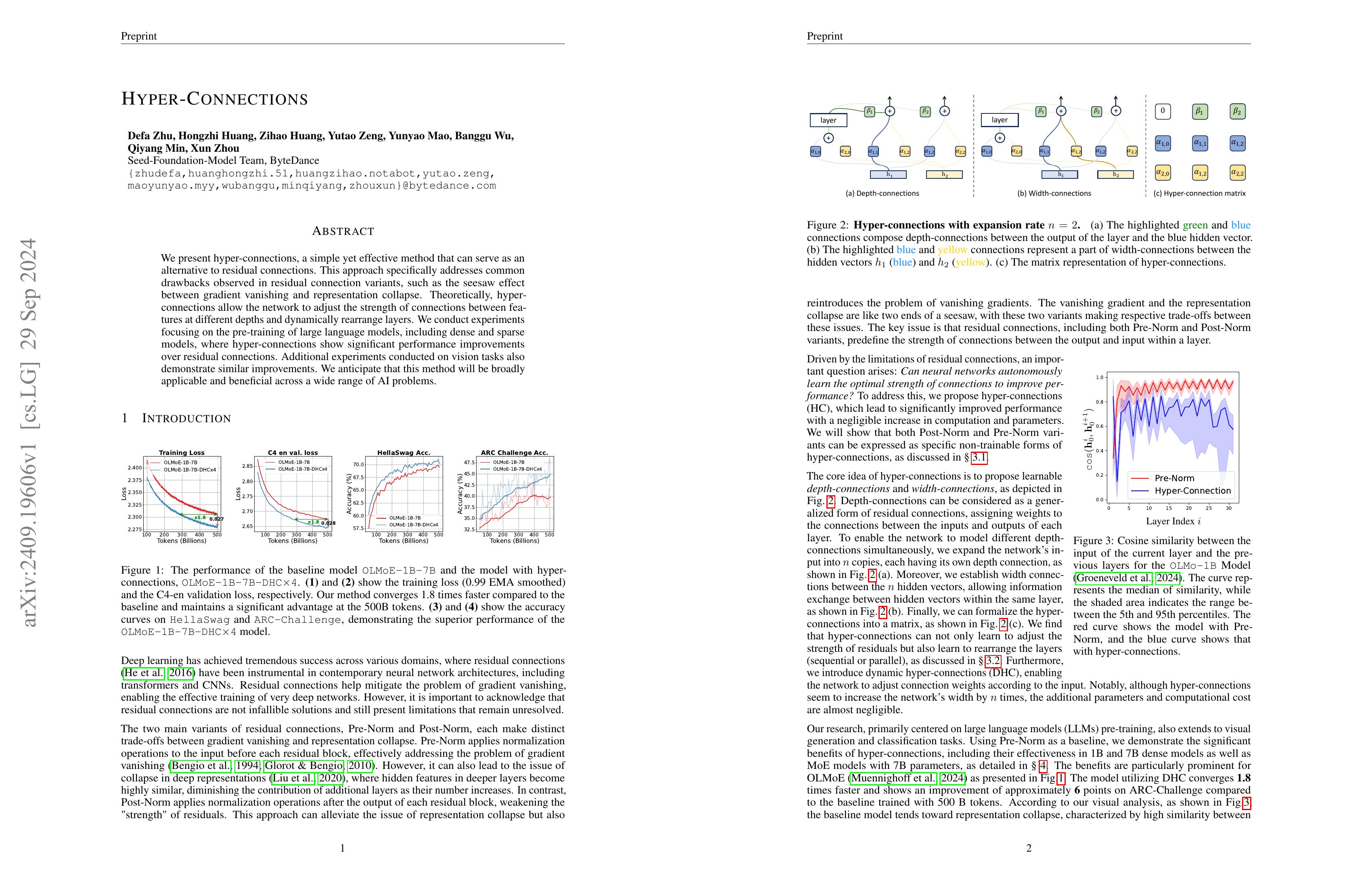
We present hyper-connections, a simple yet effective method that can serve as an alternative to residual connections. This approach specifically addresses common drawbacks observed in residual connection variants, such as the seesaw effect between gradient vanishing and representation collapse. Theoretically, hyper-connections allow the network to adjust the strength of connections between features at different depths and dynamically rearrange layers. We conduct experiments focusing on the pre-training of large language models, including dense and sparse models, where hyper-connections show significant performance improvements over residual connections. Additional experiments conducted on vision tasks also demonstrate similar improvements. We anticipate that this method will be broadly applicable and beneficial across a wide range of AI problems.
여러 개의 Residual Stream을 놓고 이 Stream들을 어떻게 업데이트 할 것인지를 학습시킨 시도라고 할 수 있겠네요. ResNet 시절의 추억에 젖게 하는 연구군요. (https://arxiv.org/abs/1904.01569)
Using multiple residual streams and learn how to update each streams. It reminds me the era of ResNets. (https://arxiv.org/abs/1904.01569)
#transformer
HybridFlow: A Flexible and Efficient RLHF Framework
(Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu)

Reinforcement Learning from Human Feedback (RLHF) is widely used in Large Language Model (LLM) alignment. Traditional RL can be modeled as a dataflow, where each node represents computation of a neural network (NN) and each edge denotes data dependencies between the NNs. RLHF complicates the dataflow by expanding each node into a distributed LLM training or generation program, and each edge into a many-to-many multicast. Traditional RL frameworks execute the dataflow using a single controller to instruct both intra-node computation and inter-node communication, which can be inefficient in RLHF due to large control dispatch overhead for distributed intra-node computation. Existing RLHF systems adopt a multi-controller paradigm, which can be inflexible due to nesting distributed computation and data communication. We propose HybridFlow, which combines single-controller and multi-controller paradigms in a hybrid manner to enable flexible representation and efficient execution of the RLHF dataflow. We carefully design a set of hierarchical APIs that decouple and encapsulate computation and data dependencies in the complex RLHF dataflow, allowing efficient operation orchestration to implement RLHF algorithms and flexible mapping of the computation onto various devices. We further design a 3D-HybridEngine for efficient actor model resharding between training and generation phases, with zero memory redundancy and significantly reduced communication overhead. Our experimental results demonstrate 1.53$\times$~20.57$\times$ throughput improvement when running various RLHF algorithms using HybridFlow, as compared with state-of-the-art baselines. HybridFlow source code is available at https://github.com/volcengine/verl.
RLHF 과정을 효율화하기 위한 프레임워크도 종종 나오는군요. RLHF는 다양한 모델을 다양한 방법으로 사용하니 그만큼 최적화의 여지가 있다고 생각할 수도 있겠네요. (또 그만큼 난이도가 높아지기도 하죠.) 대규모 RL이 LLM에서 중요한 패러다임이 되고 있는 이상 그만큼 인프라의 효율성에 신경을 써야할지도 모르겠습니다.
Frameworks for optimizing the RLHF process seem to be emerging more frequently. Given that RLHF uses various models in diverse ways, we can see there's significant room for optimization (though this also increases the complexity). As large-scale RL becomes an important paradigm for LLMs, we may need to pay more attention to the efficiency of the infrastructure supporting it.
#rlhf #framework
Can Models Learn Skill Composition from Examples?
(Haoyu Zhao, Simran Kaur, Dingli Yu, Anirudh Goyal, Sanjeev Arora)

As large language models (LLMs) become increasingly advanced, their ability to exhibit compositional generalization -- the capacity to combine learned skills in novel ways not encountered during training -- has garnered significant attention. This type of generalization, particularly in scenarios beyond training data, is also of great interest in the study of AI safety and alignment. A recent study introduced the SKILL-MIX evaluation, where models are tasked with composing a short paragraph demonstrating the use of a specified k-tuple of language skills. While small models struggled with composing even with k=3, larger models like GPT-4 performed reasonably well with k=5 and 6. In this paper, we employ a setup akin to SKILL-MIX to evaluate the capacity of smaller models to learn compositional generalization from examples. Utilizing a diverse set of language skills -- including rhetorical, literary, reasoning, theory of mind, and common sense -- GPT-4 was used to generate text samples that exhibit random subsets of k skills. Subsequent fine-tuning of 7B and 13B parameter models on these combined skill texts, for increasing values of k, revealed the following findings: (1) Training on combinations of k=2 and 3 skills results in noticeable improvements in the ability to compose texts with k=4 and 5 skills, despite models never having seen such examples during training. (2) When skill categories are split into training and held-out groups, models significantly improve at composing texts with held-out skills during testing despite having only seen training skills during fine-tuning, illustrating the efficacy of the training approach even with previously unseen skills. This study also suggests that incorporating skill-rich (potentially synthetic) text into training can substantially enhance the compositional capabilities of models.
Skill-Mix (https://arxiv.org/abs/2310.17567), 즉 필요한 능력의 수를 변화시켜 문제의 난이도를 조정하는 접근에 대해 모델을 이러한 문제에 대해 학습시켰을 때 성능이 어떻게 변화하는지를 분석한 연구.
주요한 발견은 1. 학습에서 사용하지 않은 능력들에 대해서도 일반화가 된다는 것 2. 학습에서 사용하지 않은 능력 조합의 숫자에 대해서도 일반화가 된다는 것입니다. 파인튜닝은 프리트레이닝된 모델에 잠재되어 있는 능력을 끌어낸다는 아이디어와 비슷하게 생각할 수 있을 듯 하네요. (여기서는 능력의 조합에 대한 Instruction Following 능력이 되겠죠.)
This study analyzes how model performance changes when trained on problems based on Skill-Mix (https://arxiv.org/abs/2310.17567), an approach that adjusts problem difficulty by varying the number of required skills.
The main findings are: 1. The model generalizes to skills not used in training. 2. The model generalizes to combinations of skills with numbers not used in training. This phenomenon can be thought of similarly to the idea that fine-tuning draws out capabilities latent in the pre-trained model. (In this case, it would be the capability of following instructions related to skill composition.)
#generalization #llm