



2024년 1월 7일

Scaling Laws for Floating Point Quantization Training
(Xingwu Sun, Shuaipeng Li, Ruobing Xie, Weidong Han, Kan Wu, Zhen Yang, Yixing Li, An Wang, Shuai Li, Jinbao Xue, Yu Cheng, Yangyu Tao, Zhanhui Kang, Chengzhong Xu, Di Wang, Jie Jiang)
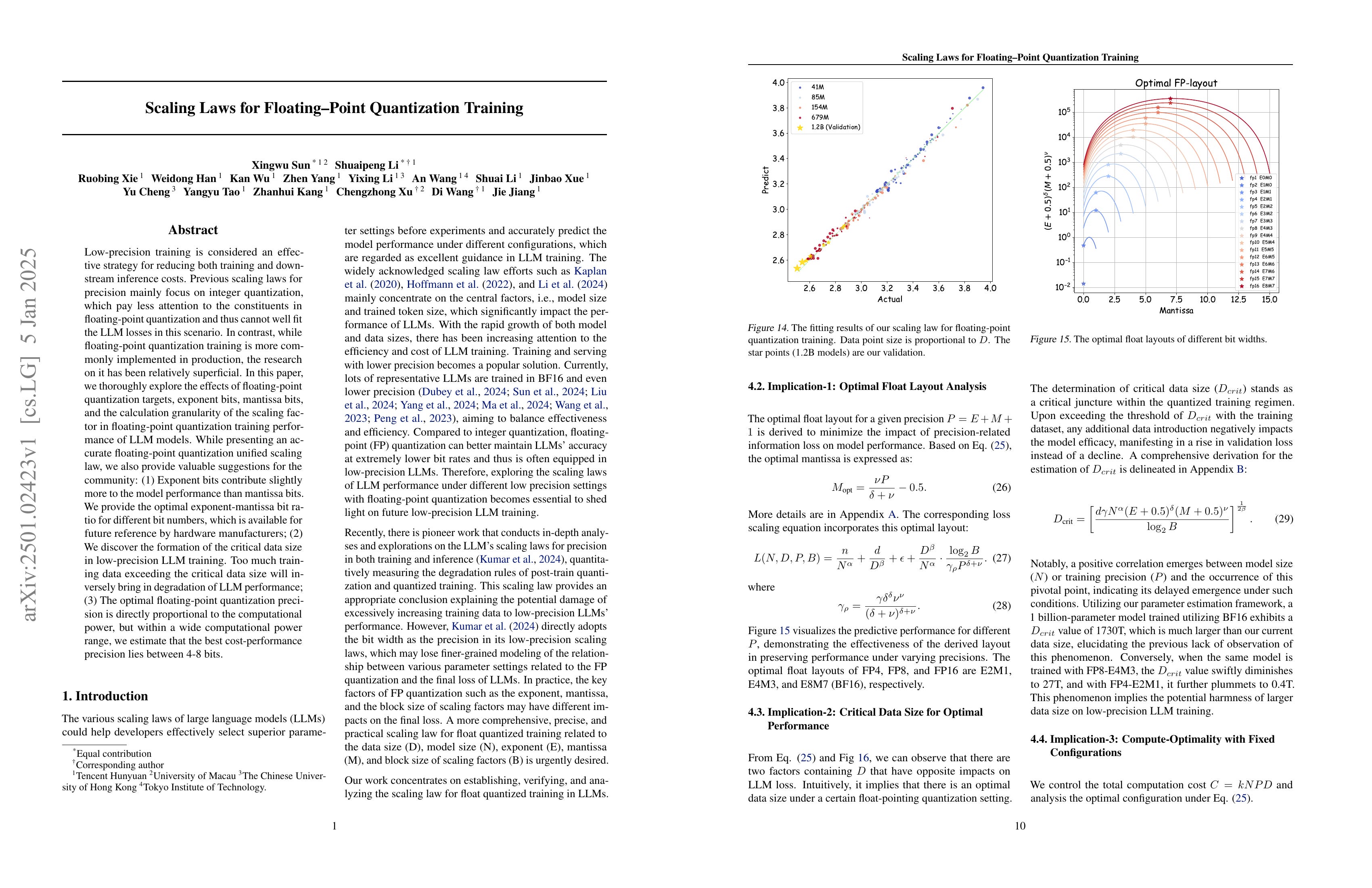
Low-precision training is considered an effective strategy for reducing both training and downstream inference costs. Previous scaling laws for precision mainly focus on integer quantization, which pay less attention to the constituents in floating-point quantization and thus cannot well fit the LLM losses in this scenario. In contrast, while floating-point quantization training is more commonly implemented in production, the research on it has been relatively superficial. In this paper, we thoroughly explore the effects of floating-point quantization targets, exponent bits, mantissa bits, and the calculation granularity of the scaling factor in floating-point quantization training performance of LLM models. While presenting an accurate floating-point quantization unified scaling law, we also provide valuable suggestions for the community: (1) Exponent bits contribute slightly more to the model performance than mantissa bits. We provide the optimal exponent-mantissa bit ratio for different bit numbers, which is available for future reference by hardware manufacturers; (2) We discover the formation of the critical data size in low-precision LLM training. Too much training data exceeding the critical data size will inversely bring in degradation of LLM performance; (3) The optimal floating-point quantization precision is directly proportional to the computational power, but within a wide computational power range, we estimate that the best cost-performance precision lies between 4-8 bits.
Quantized Training에 대한 Scaling Law. Bit width에 따른 최적 Exponent/Mantissa 등 재미있는 부분이 많네요. 그런데 여기서 사용한 Scaling Law의 함수형에 따르면 특정 Precision에서 추가로 학습하면 오히려 Validation Loss가 상승하는 변곡점이 발생합니다. 좀 낯선 아이디어군요.
This paper presents a scaling law for quantized training. There are many interesting aspects, such as the optimal exponent/mantissa ratio for specific bit widths. However, according to the functional form of the scaling law used here, there exists an inflection point for certain precisions where further training actually increases the validation loss. This seems like an unusual conclusion.
#quantization #scaling-law
PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models
(Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, Yu Cheng)

Process-level Reward Models (PRMs) are crucial for complex reasoning and decision-making tasks, where each intermediate step plays an important role in the reasoning process. Since language models are prone to various types of errors during the reasoning process, PRMs are required to possess nuanced capabilities for detecting various implicit error types in real-world scenarios. However, current benchmarks primarily focus on step correctness, failing to evaluate PRMs' performance systematically. To address this gap, we introduce PRMBench, a process-level benchmark specifically designed to assess the fine-grained error detection capabilities of PRMs. PRMBench comprises 6,216 carefully designed problems and 83,456 step-level labels, evaluating models across multiple dimensions, including simplicity, soundness, and sensitivity. In our experiments on 15 models, spanning both open-source PRMs and closed-source large language models prompted as critic models, we uncover significant weaknesses in current PRMs. These findings underscore the challenges inherent in process-level evaluation and highlight key directions for future research. We hope PRMBench can be a robust bench for advancing research on PRM evaluation and development.
PRM800K 기반으로 구축한 Process Reward Model에 대한 벤치마크. 각 스텝에 대한 평가에서 평가 기준 카테고리를 추가적으로 지정했다는 것이 재미있네요.
A benchmark for process reward models based on PRM800K. What's interesting is that they added categories of evaluation criteria for each step.
#benchmark #reward-model