



2024년 1월 30일

Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling
(Pratyush Maini, Skyler Seto, He Bai, David Grangier, Yizhe Zhang, Navdeep Jaitly)

Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased. Current scaling laws show that learning from such data requires an abundance of both compute and data, which grows with the size of the model being trained. This is infeasible both because of the large compute costs and duration associated with pre-training, and the impending scarcity of high-quality data on the web. In this work, we propose Web Rephrase Augmented Pre-training (WRAPWRAP) that uses an off-the-shelf instruction-tuned model prompted to paraphrase documents on the web in specific styles such as "like Wikipedia" or in "question-answer format" to jointly pre-train LLMs on real and synthetic rephrases. First, we show that using WRAP on the C4 dataset, which is naturally noisy, speeds up pre-training by ∼3�∼3x. At the same pre-training compute budget, it improves perplexity by more than 10% on average across different subsets of the Pile, and improves zero-shot question answer accuracy across 13 tasks by more than 2%. Second, we investigate the impact of the re-phrasing style on the performance of the model, offering insights into how the composition of the training data can impact the performance of LLMs in OOD settings. Our gains are attributed to the fact that re-phrased synthetic data has higher utility than just real data because it (i) incorporates style diversity that closely reflects downstream evaluation style, and (ii) has higher 'quality' than web-scraped data.
웹 데이터를 LLM으로 다양한 스타일을 바꾼 다음 학습시키는 방법. 노이즈를 제거하기 위한 방법이라고 할 수 있겠습니다. 노이즈를 제거하는 만큼 학습 속도에 가속이 발생하네요. 완전히 생성하는 것보다는 정보를 되도록 유지하면서 노이즈를 제거한다는 것은 꽤 유의미한 방향이 아닐까 싶습니다.
#dataset #llm #corpus
Routers in Vision Mixture of Experts: An Empirical Study
(Tianlin Liu, Mathieu Blondel, Carlos Riquelme, Joan Puigcerver)

Mixture-of-Experts (MoE) models are a promising way to scale up model capacity without significantly increasing computational cost. A key component of MoEs is the router, which decides which subset of parameters (experts) process which feature embeddings (tokens). In this paper, we present a comprehensive study of routers in MoEs for computer vision tasks. We introduce a unified MoE formulation that subsumes different MoEs with two parametric routing tensors. This formulation covers both sparse MoE, which uses a binary or hard assignment between experts and tokens, and soft MoE, which uses a soft assignment between experts and weighted combinations of tokens. Routers for sparse MoEs can be further grouped into two variants: Token Choice, which matches experts to each token, and Expert Choice, which matches tokens to each expert. We conduct head-to-head experiments with 6 different routers, including existing routers from prior work and new ones we introduce. We show that (i) many routers originally developed for language modeling can be adapted to perform strongly in vision tasks, (ii) in sparse MoE, Expert Choice routers generally outperform Token Choice routers, and (iii) soft MoEs generally outperform sparse MoEs with a fixed compute budget. These results provide new insights regarding the crucial role of routers in vision MoE models.
비전 모델에 대한 MoE 테스트. Soft MoE가 Hard MoE 보다 낫고, 각 토큰에서 Top-K Expert를 선택하는 것보다는 각 Expert에 Top-K 토큰을 할당하는 쪽이 낫다, 그리고 그 외의 변주는 그렇게 중요하지 않은 것 같다는 결과입니다.
아키텍처적인 측면에서 MoE는 탐색할 가치가 충분히 있다고 보이네요.
#moe
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
(Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, Li Yuan)

For Large Vision-Language Models (LVLMs), scaling the model can effectively improve performance. However, expanding model parameters significantly increases the training and inferring costs, as all model parameters are activated for each token in the calculation. In this work, we propose a novel training strategy MoE-tuning for LVLMs, which can constructing a sparse model with an outrageous number of parameter but a constant computational cost, and effectively addresses the performance degradation typically associated with multi-modal learning and model sparsity. Furthermore, we present the MoE-LLaVA framework, a MoE-based sparse LVLM architecture. This framework uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Our extensive experiments highlight the excellent capabilities of MoE-LLaVA in visual understanding and its potential to reduce hallucinations in model outputs. Remarkably, with just 3 billion sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at \url{https://github.com/PKU-YuanGroup/MoE-LLaVA}.
Projector Tuning -> Full Finetuning -> FFN 복붙으로 MoE Tuning의 3단 튜닝으로 만들어진 VLM. MoE를 할 수 있다면 하지 않을 이유가 없는 상황이 됐군요.
이미지와 텍스트 토큰의 Expert Assignment를 봤을 때 각 Expert에 이미지와 텍스트가 비슷한 비율로 들어가는 것이 흥미로운 부분이군요. 즉 이미지 전담 Expert가 있는 것이 아니라 한 Expert가 이미지와 텍스트를 동시에 커버한다는 의미입니다.
#moe #vision-language
InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model
(Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, Jiaqi Wang)

We introduce InternLM-XComposer2, a cutting-edge vision-language model excelling in free-form text-image composition and comprehension. This model goes beyond conventional vision-language understanding, adeptly crafting interleaved text-image content from diverse inputs like outlines, detailed textual specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that applies additional LoRA parameters exclusively to image tokens to preserve the integrity of pre-trained language knowledge, striking a balance between precise vision understanding and text composition with literary talent. Experimental results demonstrate the superiority of InternLM-XComposer2 based on InternLM2-7B in producing high-quality long-text multi-modal content and its exceptional vision-language understanding performance across various benchmarks, where it not only significantly outperforms existing multimodal models but also matches or even surpasses GPT-4V and Gemini Pro in certain assessments. This highlights its remarkable proficiency in the realm of multimodal understanding. The InternLM-XComposer2 model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
지금도 그렇지만 앞으로도 온갖 VLM들이 등장할 것 같네요. 눈에 띄는 부분은 이미지 토큰에만 LoRA를 적용하는 것과 Free-form Text-Image Composition이라는 이미지와 텍스트의 Interleaved 데이터셋입니다. 사용자가 제공한 이미지나 혹은 Retrieval한 이미지를 응답에 끼워넣을 수 있도록 구성한 데이터셋이네요.
#vision-language
Iterative Data Smoothing: Mitigating Reward Overfitting and Overoptimization in RLHF
(Banghua Zhu, Michael I. Jordan, Jiantao Jiao)
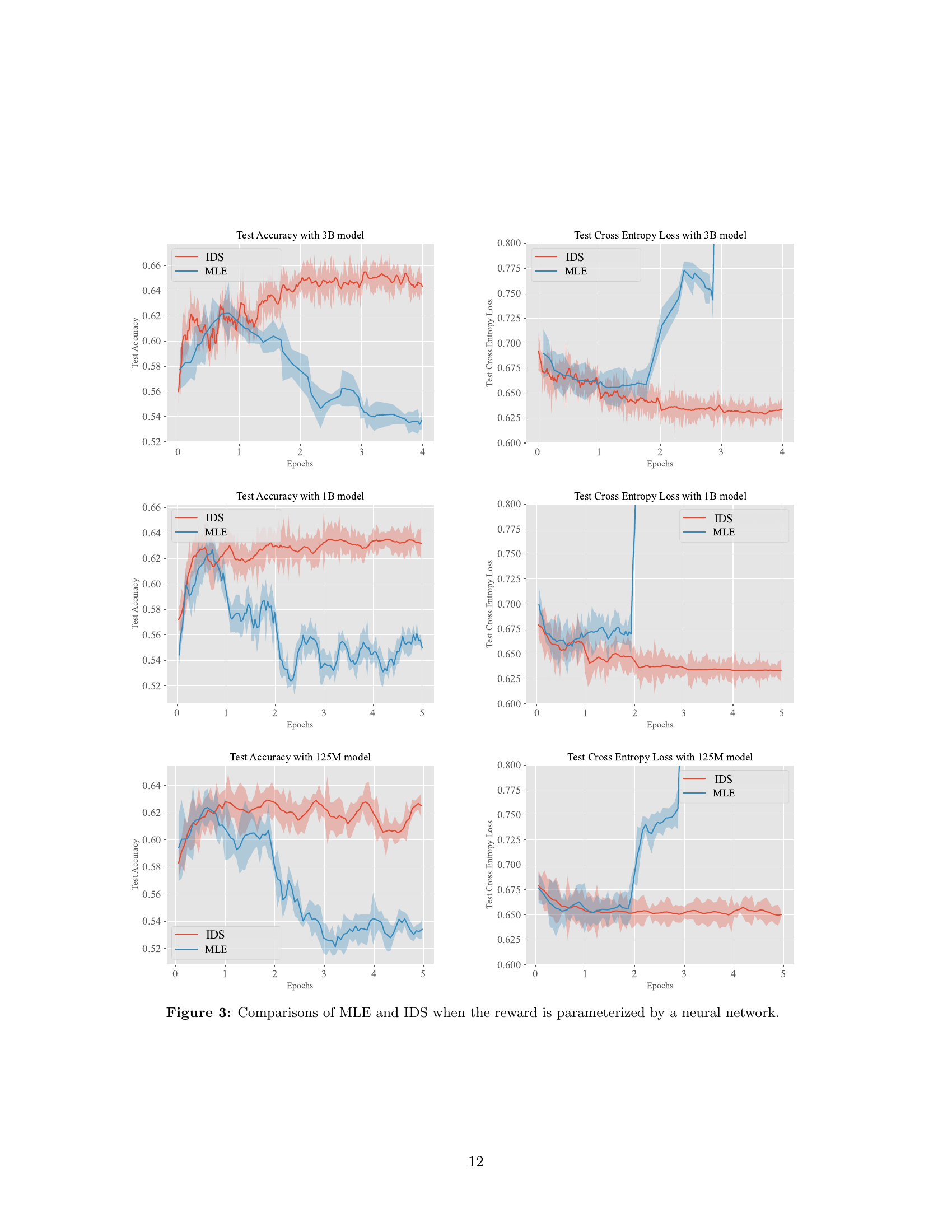
Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique that aligns language models closely with human-centric values. The initial phase of RLHF involves learning human values using a reward model from ranking data. It is observed that the performance of the reward model degrades after one epoch of training, and optimizing too much against the learned reward model eventually hinders the true objective. This paper delves into these issues, leveraging the theoretical insights to design improved reward learning algorithm termed 'Iterative Data Smoothing' (IDS). The core idea is that during each training epoch, we not only update the model with the data, but also update the date using the model, replacing hard labels with soft labels. Our empirical findings highlight the superior performance of this approach over the traditional methods.
마이클 조던을 이 문제에 대해서 보게 되네요. Reward Model Overfitting과 그로 인해 이어지는 Overoptimization 문제에 대해 다룹니다. 여기서 보는 주 원인은 Preference 데이터셋의 불균등함과 롱테일적인 특성입니다. 그러니까 많은 비교 데이터가 집중된 사례와 그렇지 않은 사례의 차이에서 발생하는 문제라고 말하고 있네요.
해법으로 제시한 것은 모델의 예측 결과로 레이블을 업데이트해나가는 방법입니다. Secrets of RLHF II의 Label Smoothing이 떠오르는군요. (https://arxiv.org/abs/2401.06080)
#reward-model
Scaling Sparse Fine-Tuning to Large Language Models
(Alan Ansell, Ivan Vulić, Hannah Sterz, Anna Korhonen, Edoardo M. Ponti)

Large Language Models (LLMs) are difficult to fully fine-tune (e.g., with instructions or human feedback) due to their sheer number of parameters. A family of parameter-efficient sparse fine-tuning (SFT) methods have proven promising in terms of performance but their memory requirements increase proportionally to the size of the LLMs. In this work, we scale sparse fine-tuning to state-of-the-art LLMs like LLaMA 2 7B and 13B. At any given time, for a desired density level, we maintain an array of parameter indices and the deltas of these parameters relative to their pretrained values. We iterate among: (a) updating the active deltas, (b) pruning indices (based on the change of magnitude of their deltas) and (c) regrowth of indices. For regrowth, we explore two criteria based on either the accumulated gradients of a few candidate parameters or their approximate momenta estimated using the efficient SM3 optimizer. We experiment with instruction-tuning of LLMs on standard dataset mixtures, finding that SFT is often superior to popular parameter-efficient fine-tuning methods like LoRA (low-rank adaptation) in terms of performance and comparable in terms of run time. We additionally show that SFT is compatible with both quantization and efficient optimizers, to facilitate scaling to ever-larger model sizes. We release the code for SFT at https://github.com/AlanAnsell/peft and for the instruction-tuning experiments at https://github.com/ducdauge/sft-llm.
Sparse Weight를 사용해 Parameter Efficient Tuning을 하는 방법. 최근에도 LoRA에 Sparse Weight를 같이 사용한 방법이 나왔었죠. (https://arxiv.org/abs/2401.04679) Sparse Weight를 사용하는 방법이 LoRA 단독으로는 충분하지 않은 영역까지 커버하는데 도움이 될지 궁금하네요. 다만 Parameter Efficient Tuning의 추가적인 가치는 파인튜닝된 다수의 모델들을 배포하는 것일 텐데 그 문제는 좀 어렵게 만들 것 같긴 합니다.
#sparsity #efficient-training