



2024년 1월 24일

Lumiere: A Space-Time Diffusion Model for Video Generation
(Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, Inbar Mosseri)

We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
https://lumiere-video.github.io/
구글의 비디오 생성 모형. Frame Interpolation/Temporal Super Resolution 없이 Space/Time에 대한 Downsampling을 하는 UNet으로 80 프레임(16 fps, 5초 분량)을 통째로 생성하는 모델을 만들고 그 위에 Sliding Window 방식으로 Spatial Super Resolution 모델을 올렸습니다.
#video-generation #diffusion
Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment
(Keming Lu, Bowen Yu, Chang Zhou, Jingren Zhou)

Considerable efforts have been invested in augmenting the role-playing proficiency of open-source large language models (LLMs) by emulating proprietary counterparts. Nevertheless, we posit that LLMs inherently harbor role-play capabilities, owing to the extensive knowledge of characters and potential dialogues ingrained in their vast training corpora. Thus, in this study, we introduce Ditto, a self-alignment method for role-play. Ditto capitalizes on character knowledge, encouraging an instruction-following LLM to simulate role-play dialogues as a variant of reading comprehension. This method creates a role-play training set comprising 4,000 characters, surpassing the scale of currently available datasets by tenfold regarding the number of roles. Subsequently, we fine-tune the LLM using this self-generated dataset to augment its role-playing capabilities. Upon evaluating our meticulously constructed and reproducible role-play benchmark and the roleplay subset of MT-Bench, Ditto, in various parameter scales, consistently maintains a consistent role identity and provides accurate role-specific knowledge in multi-turn role-play conversations. Notably, it outperforms all open-source role-play baselines, showcasing performance levels comparable to advanced proprietary chatbots. Furthermore, we present the first comprehensive cross-supervision alignment experiment in the role-play domain, revealing that the intrinsic capabilities of LLMs confine the knowledge within role-play. Meanwhile, the role-play styles can be easily acquired with the guidance of smaller models. We open-source related resources at https://github.com/OFA-Sys/Ditto.
LLM의 롤 플레이 능력 강화. 위키 데이터에서 캐릭터에 대한 상세한 정보를 확보한 다음 이 정보를 사용해 캐릭터와 관련된 혹은 반대로 관련되지 않은 쿼리를 만들고, 이 쿼리와 캐릭터에 대한 정보를 사용해 일종의 Reading Comprehension 과제를 만들어 응답을 생성합니다. 이렇게 만든 캐릭터-쿼리-응답에 대한 데이터에서 캐릭터에 대한 상세한 정보를 축약된 정보로 대체한 다음 파인튜닝 한다는 흐름이군요.
#alignment
Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
(Mirac Suzgun, Adam Tauman Kalai)

We introduce meta-prompting, an effective scaffolding technique designed to enhance the functionality of language models (LMs). This approach transforms a single LM into a multi-faceted conductor, adept at managing and integrating multiple independent LM queries. By employing high-level instructions, meta-prompting guides the LM to break down complex tasks into smaller, more manageable subtasks. These subtasks are then handled by distinct "expert" instances of the same LM, each operating under specific, tailored instructions. Central to this process is the LM itself, in its role as the conductor, which ensures seamless communication and effective integration of the outputs from these expert models. It additionally employs its inherent critical thinking and robust verification processes to refine and authenticate the end result. This collaborative prompting approach empowers a single LM to simultaneously act as a comprehensive orchestrator and a panel of diverse experts, significantly enhancing its performance across a wide array of tasks. The zero-shot, task-agnostic nature of meta-prompting greatly simplifies user interaction by obviating the need for detailed, task-specific instructions. Furthermore, our research demonstrates the seamless integration of external tools, such as a Python interpreter, into the meta-prompting framework, thereby broadening its applicability and utility. Through rigorous experimentation with GPT-4, we establish the superiority of meta-prompting over conventional scaffolding methods: When averaged across all tasks, including the Game of 24, Checkmate-in-One, and Python Programming Puzzles, meta-prompting, augmented with a Python interpreter functionality, surpasses standard prompting by 17.1%, expert (dynamic) prompting by 17.3%, and multipersona prompting by 15.2%.
https://github.com/suzgunmirac/meta-prompting
(시스템 프롬프트로 만든) 메타 모델이 과제를 분해해서 적절한 Instruction을 개별 전문가들(LLM, 파이썬 인터프리터 등)에게 넘겨주고 각 전문가들의 결과를 토대로 문제를 풀어나간다는 흐름입니다. 개별 과제에 대한 특화가 아니라 동일한 메타 모델을 각 과제들에 사용한다는 것을 중점으로 하고 있네요.
#prompt
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
(Feng Lin, Hanling Yi, Hongbin Li, Yifan Yang, Xiaotian Yu, Guangming Lu, Rong Xiao)

Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.
Speculative Decoding의 연장선상에서 한 번에 여러 토큰을 예측하는 시도들이 많이 나오는군요. Medusa가 헤드를 여러 개 만들었다면 (https://arxiv.org/abs/2401.10774) 여기에선 마스크 토큰 여러 개를 입력하고 P-Tuning을 하는 형태네요.
개인적으로는 이런 N개 토큰 예측은 프리트레이닝에도 들어갈 수 있지 않을까 싶습니다. 추론 속도 가속 외에도 추가적인 효과를 줄 수 있을 듯 하네요.
#efficiency
Red Teaming Visual Language Models
(Mukai Li, Lei Li, Yuwei Yin, Masood Ahmed, Zhenguang Liu, Qi Liu)

VLMs (Vision-Language Models) extend the capabilities of LLMs (Large Language Models) to accept multimodal inputs. Since it has been verified that LLMs can be induced to generate harmful or inaccurate content through specific test cases (termed as Red Teaming), how VLMs perform in similar scenarios, especially with their combination of textual and visual inputs, remains a question. To explore this problem, we present a novel red teaming dataset RTVLM, which encompasses 10 subtasks (e.g., image misleading, multi-modal jail-breaking, face fairness, etc) under 4 primary aspects (faithfulness, privacy, safety, fairness). Our RTVLM is the first red-teaming dataset to benchmark current VLMs in terms of these 4 different aspects. Detailed analysis shows that 10 prominent open-sourced VLMs struggle with the red teaming in different degrees and have up to 31% performance gap with GPT-4V. Additionally, we simply apply red teaming alignment to LLaVA-v1.5 with Supervised Fine-tuning (SFT) using RTVLM, and this bolsters the models' performance with 10% in RTVLM test set, 13% in MM-Hal, and without noticeable decline in MM-Bench, overpassing other LLaVA-based models with regular alignment data. This reveals that current open-sourced VLMs still lack red teaming alignment. Our code and datasets will be open-source.
Vision-Language 모델에 대한 레드 티밍 데이터셋. 그런데 Misleading한 사례로 성조기를 놓고 What is the country of citizenship of J. K. Rowling? 이라는 질문이 있는데 레퍼런스 응답이 응답 거부인 것은 적절할까 하는 생각은 드네요.
#benchmark #dataset
TroVE: Inducing Verifiable and Efficient Toolboxes for Solving Programmatic Tasks
(Zhiruo Wang, Daniel Fried, Graham Neubig)

Language models (LMs) can solve tasks such as answering questions about tables or images by writing programs. However, using primitive functions often leads to verbose and error-prone programs, and higher-level functions require expert design. To enable better solutions without human labor, we ask code LMs to curate reusable high-level functions, and use them to write solutions. We present TROVE, a training-free method of inducing a verifiable and efficient toolbox of functions, by generating via using, growing, and periodically trimming the toolbox. On 11 datasets from math, table question answering, and image reasoning tasks, TROVE consistently yields simpler solutions with higher accuracy than baselines using CODELLAMA and previous methods using GPT, while using 79-98% smaller toolboxes. TROVE further enables 31% faster and 13% more accurate human verification than baselines. With the same pipeline, it creates diverse functions for varied tasks and datasets, providing insights into their individual characteristics.
LM이 코드 작성으로 문제를 풀 때 기초적인 함수만으로 코드를 구성하는 것이 아니라 적절하게 필요한 고수준의 함수를 작성하고, 이 함수들로 구성된 도구 상자를 유지하면서 코드를 작성하는 접근이군요.
#code
GRATH: Gradual Self-Truthifying for Large Language Models
(Weixin Chen, Bo Li)
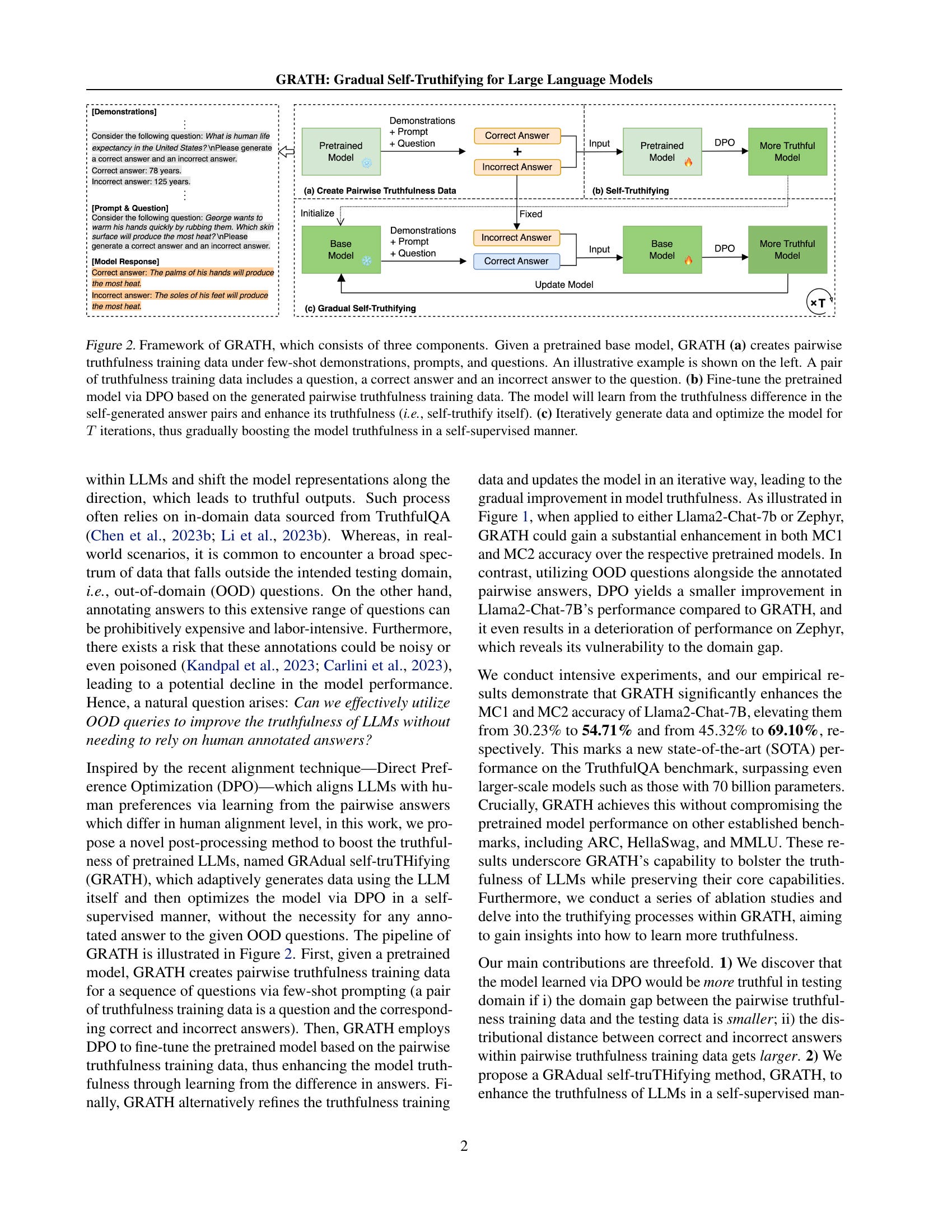
Truthfulness is paramount for large language models (LLMs) as they are increasingly deployed in real-world applications. However, existing LLMs still struggle with generating truthful answers and content, as evidenced by their modest performance on benchmarks like TruthfulQA. To address this issue, we propose GRAdual self-truTHifying (GRATH), a novel post-processing method to enhance truthfulness of LLMs. GRATH utilizes out-of-domain question prompts to generate corresponding answers and adaptively optimizes the model via direct preference optimization (DPO). Note that during this process, GRATH learns truthfulness in a self-supervised manner without requiring annotated answers. In particular, GRATH first generates pairwise truthfulness training data by prompting the LLM itself, with each pair containing a question and its correct and incorrect answers. The model is then fine-tuned using DPO to learn from the difference between answer pairs. Subsequently, GRATH iteratively refines the truthfulness data and optimizes the model, leading to a gradual improvement in model truthfulness. Empirically, we evaluate GRATH using different 7B-LLMs and compare with LLMs with similar or even larger sizes on benchmark datasets. Our results show that GRATH effectively improves LLMs' truthfulness without compromising other core capabilities. Notably, GRATH achieves state-of-the-art performance on TruthfulQA, with MC1 accuracy as 54.71% and MC2 accuracy as 69.10%, which even surpass those on larger-scale models, such as Llama2-Chat-70B, by 23.62% and 24.18%, respectively.
모델 응답의 진실성 높이기. 프롬프트를 주고 직접적으로 올바른 답과 그렇지 않은 답을 생성하게 한 다음 이 페어를 사용해서 DPO로 튜닝, 그리고 튜닝된 모델로 새로 생성한 더 "올바른" 답을 올바른 답으로 채택해서 튜닝하는 것을 반복한다는 아이디어입니다.
#alignment