



2024년 1월 18일

HippoAttention
FP8 Attention들이 나오기 시작하는군요. (https://blog.fireworks.ai/fireattention-serving-open-source-models-4x-faster-than-vllm-by-quantizing-with-no-tradeoffs-a29a85ad28d0) Flash Attention v2의 1.5 ~ 3배 가량의 수치를 보여주고 있네요.
저도 FP8을 써보고 싶네요. 4090이라도 구해와야할지.
#efficiency
Solving olympiad geometry without human demonstrations
(Trie H. Trinh, Yukuai Wu, Quoc V. Le, He He, Thang Luong)
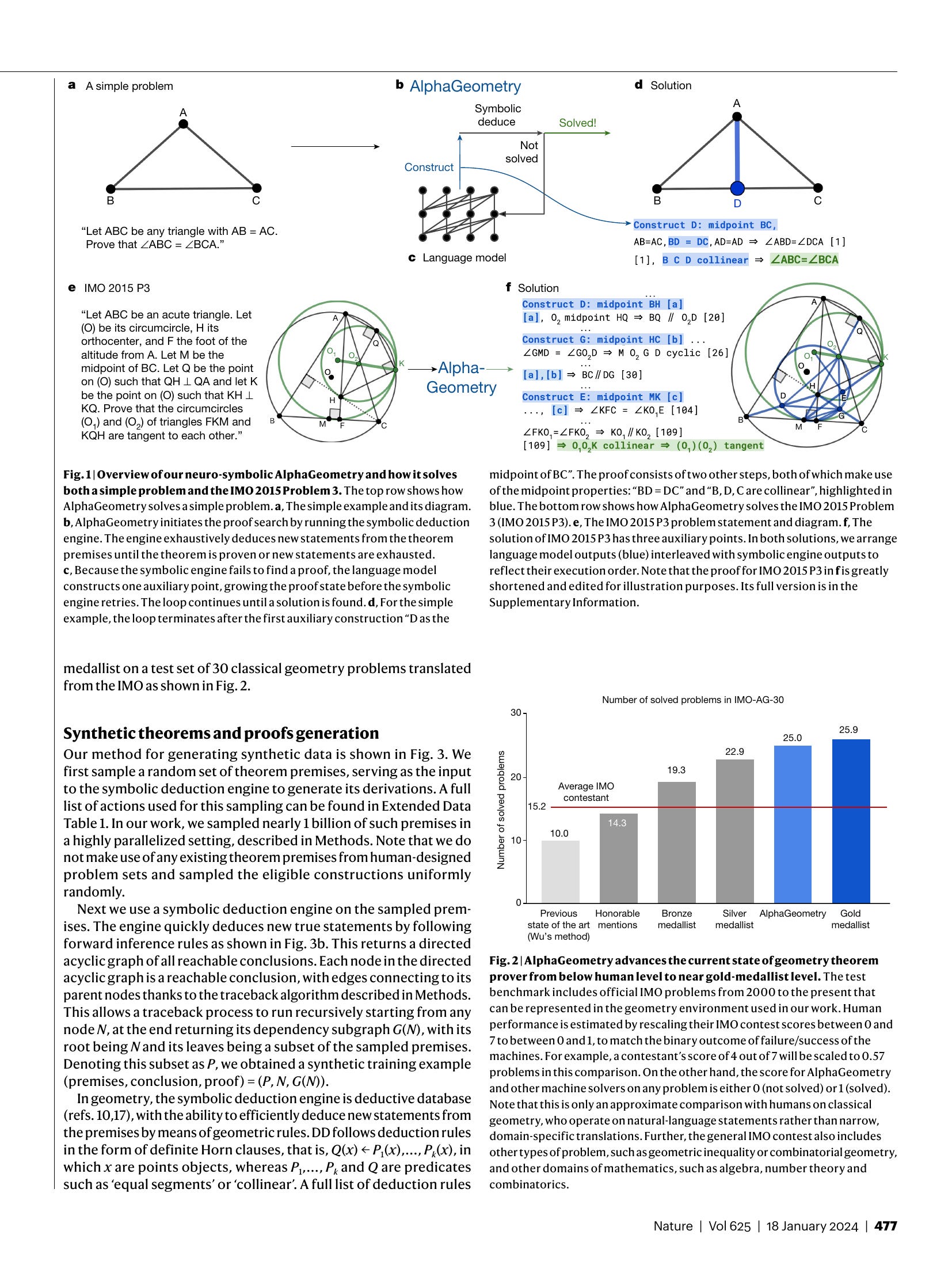
Proving mathematical theorems at the olympiad level represents a notable milestone in human-level automated reasoning, owing to their reputed difficulty among the world’s best talents in pre-university mathematics. Current machine-learning approaches, however, are not applicable to most mathematical domains owing to the high cost of translating human proofs into machine-verifiable format. The problem is even worse for geometry because of its unique translation challenges, resulting in severe scarcity of training data. We propose AlphaGeometry, a theorem prover for Euclidean plane geometry that sidesteps the need for human demonstrations by synthesizing millions of theorems and proofs across different levels of complexity. AlphaGeometry is a neuro-symbolic system that uses a neural language model, trained from scratch on our large-scale synthetic data, to guide a symbolic deduction engine through infinite branching points in challenging problems. On a test set of 30 latest olympiad-level problems, AlphaGeometry solves 25, outperforming the previous best method that only solves ten problems and approaching the performance of an average International Mathematical Olympiad (IMO) gold medallist. Notably, AlphaGeometry produces human-readable proofs, solves all geometry problems in the IMO 2000 and 2015 under human expert evaluation and discovers a generalized version of a translated IMO theorem in 2004.
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/ https://github.com/google-deepmind/alphageometry
딥마인드의 올림피아드 기하학 문제를 푸는 시스템. LM이 정의를 만들고 기호 기반 엔진이 전제와 정의로부터 결론들을 연역해나가는 것을 반복해서 증명에 도달해나가는 방법이군요.
데이터 전체를 합성해서 만들었는데 이 데이터의 구성 과정이 핵심이라고 할 수 있겠네요. 전제를 랜덤 샘플한 다음 이 전제에서 유도되는 결론들을 연역하고 이 연역 과정을 기반으로 결론들의 그래프를 만듭니다. 이렇게 하면 임의의 문제와 그에 대한 답을 생성하는 것이 되죠.
여기서 증명 시스템을 만들기 위해서는 정의를 생성할 수 있어야 하는데 이 정의는 결론에 포함되지 않지만 그래프에는 포함된 전제들을 사용합니다. 전제와 결론을 주고 정의들을 예측하게 만드는 것이죠. (이 부분이 좀 헷갈리긴 합니다.)
#search #symbolic
Asynchronous Local-SGD Training for Language Modeling
(Bo Liu, Rachita Chhaparia, Arthur Douillard, Satyen Kale, Andrei A. Rusu, Jiajun Shen, Arthur Szlam, Marc'Aurelio Ranzato)

Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
구글은 Local, Async SGD를 계속 실험해보는군요. (Local SGD를 해봤으니 Async도 해보자 정도의 발상일 수도 있겠습니다.) Gemini에서도 데이터센터를 연결해서 학습했다는 걸 생각해보면 이 계통 방법이 매력적으로 보일 수도 있겠다 싶습니다.
여기서는 Async + Local 세팅에서 이유는 잘 모르겠지만 Outer Loop의 모멘텀 업데이트 과정에서 문제가 생긴다는 것으로 보고 모멘텀 업데이트의 횟수를 줄이는 방식으로 대응했습니다.
실험 규모도 작고 더 큰 모델에서 어떤 문제가 터질지 모르겠지만 만약 성공적으로 적용할 수 있다면 가뜩이나 많은 연산력이 다시 한 번 부스트 되는 효과가 있겠네요.
#efficient_training
ReFT: Reasoning with Reinforced Fine-Tuning
(Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, Hang Li)

One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
CoT를 하게 한 다음 최종 답이 맞는지로 Reward를 주고 PPO. (너무나 당연한 소리인 것 같긴 하지만) 답을 구할 수 있으면 할 수 있는 것이 많다는 사례가 하나 추가되는군요.
Multiple Choice 문제에서는 답의 가짓수가 적으니 CoT는 틀렸는데 답은 맞을 경우가 있고 그 경우에 문제가 생기는 사례를 발견했네요. 재미있습니다.
#rl
GATS: Gather-Attend-Scatter
(Konrad Zolna, Serkan Cabi, Yutian Chen, Eric Lau, Claudio Fantacci, Jurgis Pasukonis, Jost Tobias Springenberg, Sergio Gomez Colmenarejo)

As the AI community increasingly adopts large-scale models, it is crucial to develop general and flexible tools to integrate them. We introduce Gather-Attend-Scatter (GATS), a novel module that enables seamless combination of pretrained foundation models, both trainable and frozen, into larger multimodal networks. GATS empowers AI systems to process and generate information across multiple modalities at different rates. In contrast to traditional fine-tuning, GATS allows for the original component models to remain frozen, avoiding the risk of them losing important knowledge acquired during the pretraining phase. We demonstrate the utility and versatility of GATS with a few experiments across games, robotics, and multimodal input-output systems.
여러 모델들을 연결하는 방법. 서로 다른 모델의 레이어들 사이에 GATS라는 모델의 레이어들을 끼워넣는 방식입니다. GATS는 서로 다른 모델의 임베딩에서 각각 최근 임베딩 N개를 가져와서 Attention하고 원 모델의 임베딩으로 Projection 하는 구조네요.
로봇 조작이나 게임 같은 걸 하다가 아주 가볍게(?) MaskGIT과 Chinchilla LM을 GATS로 연결해서 ViT를 학습하는 것과 ViT와 Chinchilla LM을 GATS로 조합하고 MaskGIT & Autoregressive LM으로 학습해서 이미지 캡셔닝과 Text2Image 학습을 한 사례를 보여줍니다.
#multimodal #adapter #efficient_training
Deductive Closure Training of Language Models for Coherence, Accuracy, and Updatability
(Afra Feyza Akyürek, Ekin Akyürek, Leshem Choshen, Derry Wijaya, Jacob Andreas)
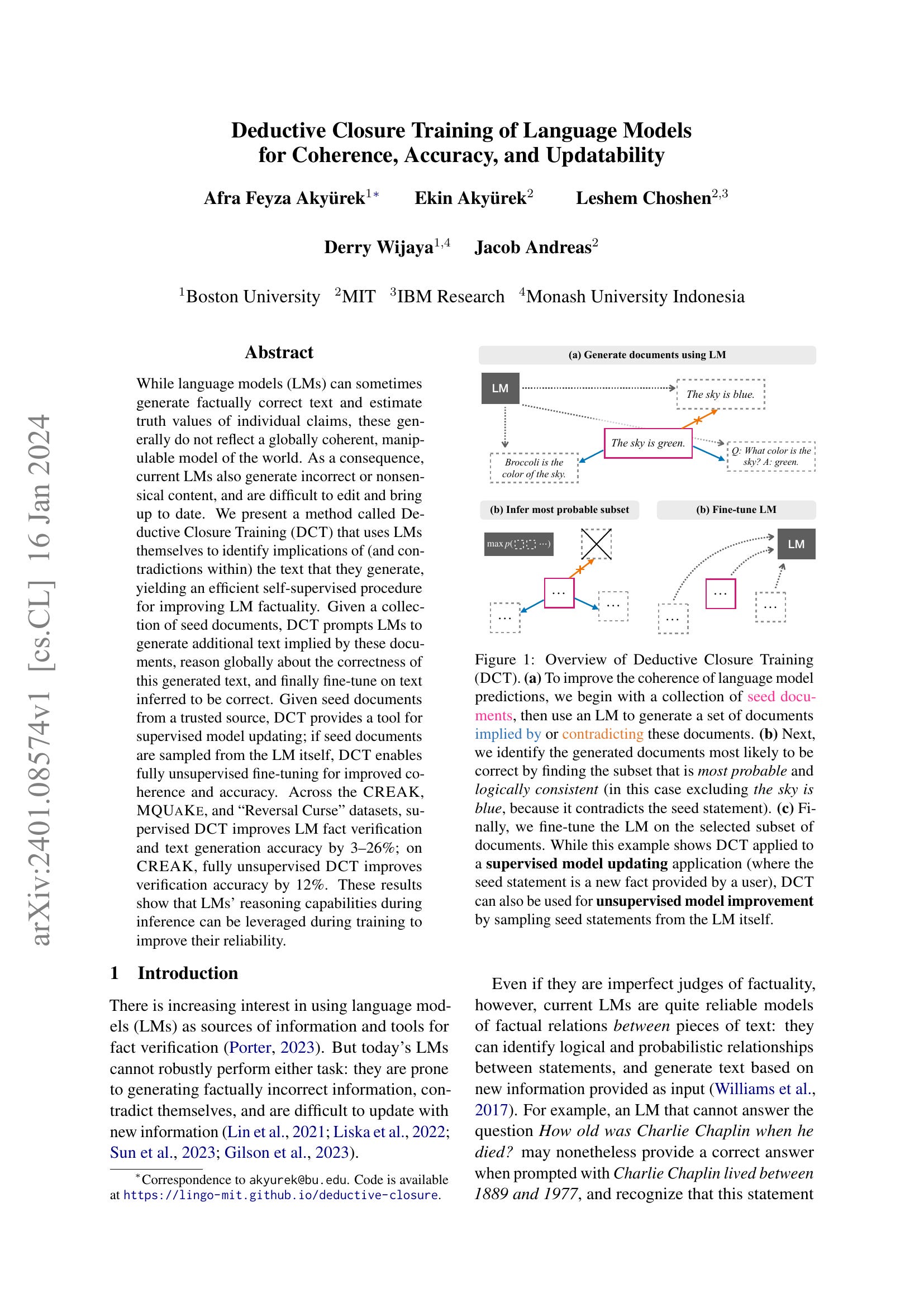
While language models (LMs) can sometimes generate factually correct text and estimate truth values of individual claims, these generally do not reflect a globally coherent, manipulable model of the world. As a consequence, current LMs also generate incorrect or nonsensical content, and are difficult to edit and bring up to date. We present a method called Deductive Closure Training (DCT) that uses LMs themselves to identify implications of (and contradictions within) the text that they generate, yielding an efficient self-supervised procedure for improving LM factuality. Given a collection of seed documents, DCT prompts LMs to generate additional text implied by these documents, reason globally about the correctness of this generated text, and finally fine-tune on text inferred to be correct. Given seed documents from a trusted source, DCT provides a tool for supervised model updating; if seed documents are sampled from the LM itself, DCT enables fully unsupervised fine-tuning for improved coherence and accuracy. Across the CREAK, MQUaKE, and Reversal Curse datasets, supervised DCT improves LM fact verification and text generation accuracy by 3-26%; on CREAK fully unsupervised DCT improves verification accuracy by 12%. These results show that LMs' reasoning capabilities during inference can be leveraged during training to improve their reliability.
사실 관계 추론 능력을 향상시키기 위한 데이터를 구축하는 방법. 문서를 가져와서 그 문서를 기반으로 문서가 함의(Implication)하거나 혹은 모순(Contradiction)이 되는 문서들을 생성합니다. 그리고 이 문서들에 대한 LM의 확률과 논리적 일관성, 즉 모두 함의이거나 모순일 것이라는 기준으로 필터링 하는 방식이네요.
논리적 구조와 원본 문서라는 정보원을 통해 합성 데이터를 만들었다고 생각할 수 있지 않을까 싶네요. 합성 데이터에서 가장 흥미로운 부분은 어떻게 정보를 주입할 것인가이니까요.
#synthetic-data
SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
(Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, Saining Xie)

We present Scalable Interpolant Transformers (SiT), a family of generative models built on the backbone of Diffusion Transformers (DiT). The interpolant framework, which allows for connecting two distributions in a more flexible way than standard diffusion models, makes possible a modular study of various design choices impacting generative models built on dynamical transport: using discrete vs. continuous time learning, deciding the objective for the model to learn, choosing the interpolant connecting the distributions, and deploying a deterministic or stochastic sampler. By carefully introducing the above ingredients, SiT surpasses DiT uniformly across model sizes on the conditional ImageNet 256x256 benchmark using the exact same backbone, number of parameters, and GFLOPs. By exploring various diffusion coefficients, which can be tuned separately from learning, SiT achieves an FID-50K score of 2.06.
Stochastic Interpolant 프레임워크 기반으로 Diffusion 모델을 보다 유연하게 만들어서 Continuous Time, Score 대신 Velocity를 사용, 데이터와 노이즈 분포에 대한 다양한 Interpolant, Diffusion Coefficient에 대한 변경 등등을 가능하게 만든 다음 이 세팅들에 대한 비교를 한 결과입니다. Stochastic Interpolant를 선행적으로 봐야할 듯 한데 이것 자체가 만만치 않군요. (https://arxiv.org/abs/2303.08797)

(https://x.com/srush_nlp/status/1741161984928920027)
#diffusion