



2024년 1월 10일

MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
(Weimin Wang, Jiawei Liu, Zhijie Lin, Jiangqiao Yan, Shuo Chen, Chetwin Low, Tuyen Hoang, Jie Wu, Jun Hao Liew, Hanshu Yan, Daquan Zhou, Jiashi Feng)

The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. Benefiting from these architecture designs, MagicVideo-V2 can generate an aesthetically pleasing, high-resolution video with remarkable fidelity and smoothness. It demonstrates superior performance over leading Text-to-Video systems such as Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion model via user evaluation at large scale.
https://magicvideov2.github.io/
Bytedance의 비디오 생성 모델. 사실 전체 시스템에 대한 요약에 가깝네요. 텍스트 -> 이미지, 이미지 -> 비디오 (Animatediff), 비디오 Super Resolution, 프레임 보간 순서입니다.
#video_generation
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
(Zhen Qin, Weigao Sun, Dong Li, Xuyang Shen, Weixuan Sun, Yiran Zhong)
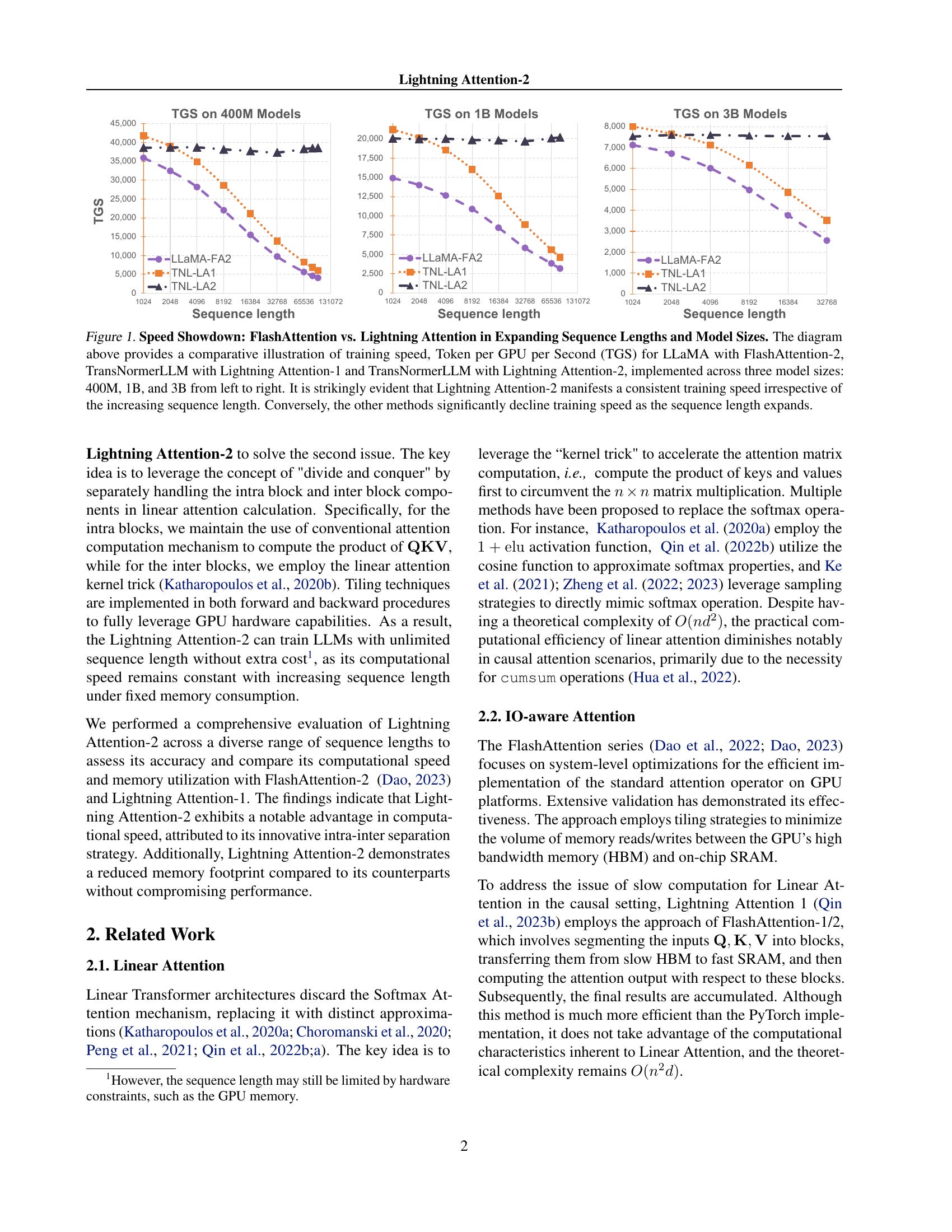
Linear attention is an efficient attention mechanism that has recently emerged as a promising alternative to conventional softmax attention. With its ability to process tokens in linear computational complexities, linear attention, in theory, can handle sequences of unlimited length without sacrificing speed, i.e., maintaining a constant training speed for various sequence lengths with a fixed memory consumption. However, due to the issue with cumulative summation (cumsum), current linear attention algorithms cannot demonstrate their theoretical advantage in a causal setting. In this paper, we present Lightning Attention-2, the first linear attention implementation that enables linear attention to realize its theoretical computational benefits. To achieve this, we leverage the thought of tiling, separately handling the intra-block and inter-block components in linear attention calculation. Specifically, we utilize the conventional attention computation mechanism for the intra-blocks and apply linear attention kernel tricks for the inter-blocks. A tiling technique is adopted through both forward and backward procedures to take full advantage of the GPU hardware. We implement our algorithm in Triton to make it IO-aware and hardware-friendly. Various experiments are conducted on different model sizes and sequence lengths. Lightning Attention-2 retains consistent training and inference speed regardless of input sequence length and is significantly faster than other attention mechanisms. The source code is available at https://github.com/OpenNLPLab/lightning-attention.
Linear Attention에 대한 고속 구현. 역설적이다 싶지만 특히 Long Context에서 Recursive하게 계산할 수 있다는 것이 메리트가 되네요.
Linear Attention이 의미가 있는가? 라는 문제가 중요하겠죠. https://hazyresearch.stanford.edu/blog/2023-12-11-zoology2-based Sub Quadratic 아키텍처에 대한 최근 결과들을 보면 지켜볼만하지 않은가 싶습니다.
#efficiency